
Prometheus & Grafana trên AWS EKS: Observability chuyên nghiệp

Bài trước chúng ta đã xây dựng Triển Khai Hệ Thống AWS EKS kết hợp RDS, S3, Lambda và CI/CD với Jenkins .Bạn đã xây dựng xong cụm AWS EKS, ứng dụng đã "Running", nhưng làm sao để biết nó đang "thở" thế nào? Liệu CPU có đang quá tải hay RAM có sắp chạm đỉnh? Chào mừng bạn đến với thế giới của Observability. Trong bài viết này, chúng ta sẽ cùng triển khai bộ đôi quyền lực Prometheus & Grafana lên EKS bằng Helm, đồng thời xử lý các bài toán thực tế về tài nguyên trên AWS.
1. Observability là gì? Tại sao cần nó?
Observability (Khả năng quan sát) không chỉ đơn thuần là Monitoring (Giám sát). Nếu Monitoring báo cho bạn biết hệ thống "sống hay chết", thì Observability giúp bạn trả lời câu hỏi: "Tại sao nó lại hoạt động như vậy?".
Thông qua việc thu thập Metrics (chỉ số), chúng ta có thể đưa ra các quyết định chính xác về việc tối ưu hóa hạ tầng và dự báo rủi ro trước khi hệ thống sập.
2. Triển khai Prometheus & Grafana bằng Helm
Để cài đặt nhanh chóng và chuẩn công nghiệp, chúng ta sử dụng Helm Chart. Tuy nhiên, với các cụm Lab nhỏ, việc dùng cấu hình mặc định sẽ ngốn rất nhiều tài nguyên.
Bước 1: Khai báo Repository
brew install helm
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
Bước 2: Tạo file cấu hình tối ưu values-micro.yaml
Để tránh việc Prometheus "ăn sạch" RAM của Node, chúng ta cần giới hạn tài nguyên (Resources Limit) và tắt các thành phần chưa cần thiết:
# Tắt Alertmanager để tiết kiệm tài nguyên cho Lab
alertmanager:
enabled: false
# Giới hạn RAM/CPU cho Prometheus
prometheus:
prometheusSpec:
retention: 12h # Chỉ lưu dữ liệu trong 12 giờ
resources:
requests:
memory: 256Mi
cpu: 50m
limits:
memory: 512Mi
# Giới hạn cho Grafana
grafana:
resources:
requests:
memory: 128Mi
limits:
memory: 256Mi
3. Bài học thực chiến: Giới hạn tài nguyên trên AWS (t3.micro vs t3.medium)
Một sai lầm phổ biến khi chạy Lab trên AWS Free Tier (t3.micro) là hệ thống sẽ báo lỗi FailedScheduling với thông báo: "Too many pods" hoặc "Insufficient memory".
| Đặc điểm | t3.micro | t3.medium (Khuyên dùng) |
| RAM | 1 GB | 4 GB |
| Giới hạn Pod (ENI) | ~4 Pods/Node | ~17 Pods/Node |
| Trạng thái | Thường xuyên Pending |
Chạy mượt mà App + Monitoring |
Lưu ý: Trên EKS, mỗi Pod cần một địa chỉ IP riêng. Các dòng máy nhỏ như
t3.microbị giới hạn số lượng IP (ENI), dẫn đến việc bạn không thể cài đặt đủ bộ Monitoring dù RAM vẫn còn.
4. Nâng cấp hạ tầng bằng Terraform (IaC)
Nếu cụm của bạn đang bị nghẽn cổ chai, đừng ngần ngại nâng cấp Node Group thông qua Terraform. Đây là cách tiếp cận hạ tầng dưới dạng code (Infrastructure as Code) chuyên nghiệp.
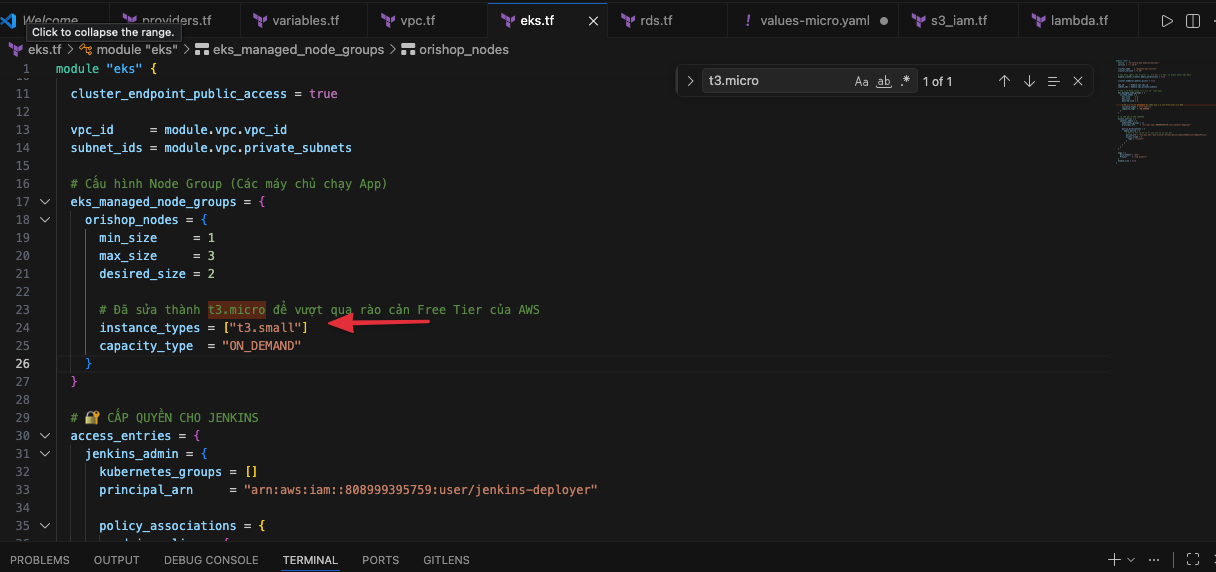
-
Mở file cấu hình EKS (ví dụ
eks.tf). -
Sửa
instance_types = ["t3.micro"]thànhinstance_types = ["t3.medium"]. (Nhưng với chế độ con nhà nghèo của mình thì mình chỉ dùng t3.small thôi nhé ) -
Thực thi lệnh:
terraform apply
AWS sẽ tự động thực hiện quá trình "Rolling Update", thay thế các Node cũ bằng Node mới mạnh mẽ hơn.
5. Cài đặt và Nghiệm thu
Sau khi hạ tầng đã sẵn sàng, hãy tiến hành cài đặt:
helm install my-monitor prometheus-community/kube-prometheus-stack \
-n monitoring --create-namespace -f values-micro.yaml
Truy cập giao diện Grafana
Sử dụng kỹ thuật Port-forwarding để truy cập từ máy cá nhân:
kubectl port-forward svc/my-monitor-grafana 3000:80 -n monitoring
-
URL:
http://localhost:3000 -
User:
admin -
Password: Lấy bằng lệnh
kubectl get secret --namespace monitoring my-monitor-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echoKết quả đạt được
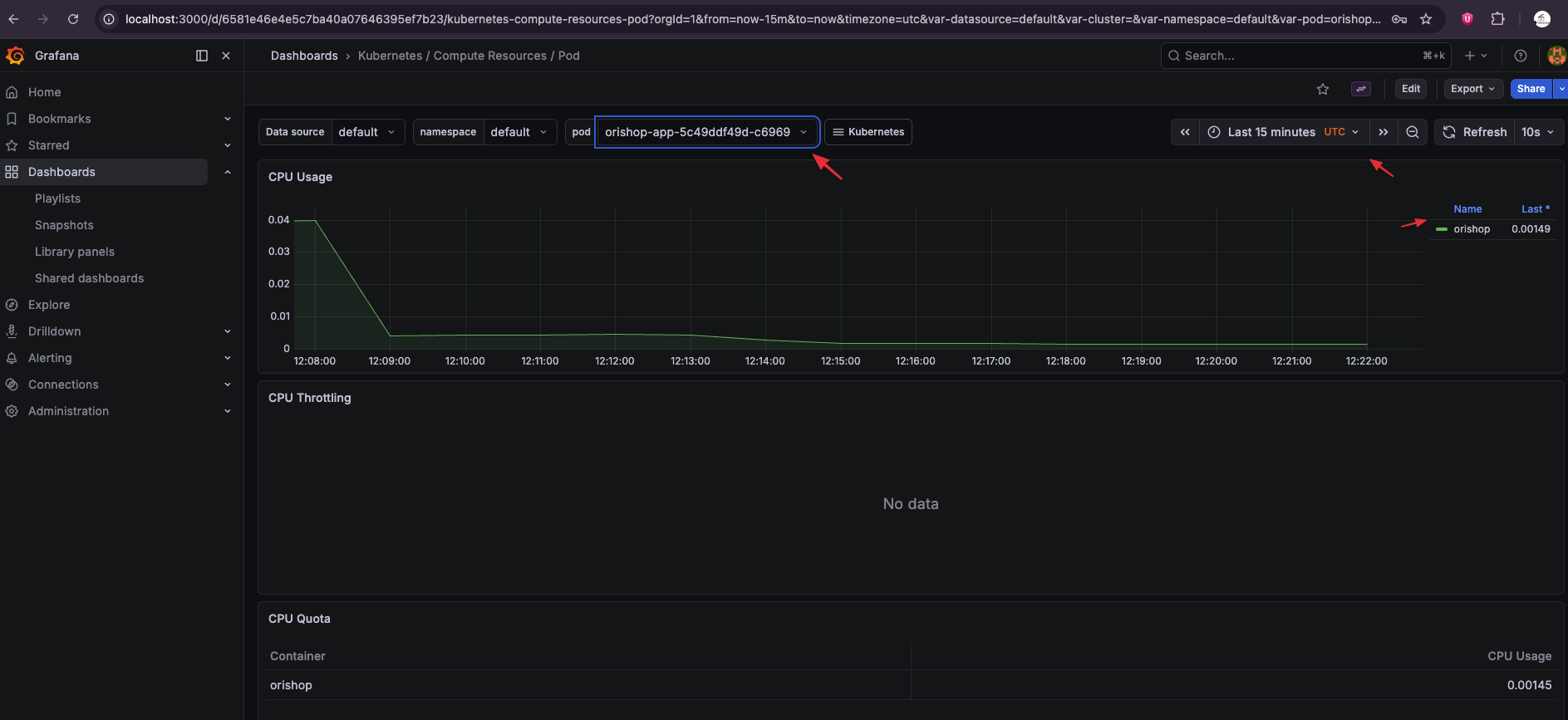
Trong Grafana, hãy tìm Dashboard: "Kubernetes / Compute Resources / Pod". Tại đây, bạn sẽ thấy toàn bộ "nhịp tim" của ứng dụng: từ mức độ ngốn CPU cho đến dung lượng RAM thực tế mà các Pod đang sử dụng.
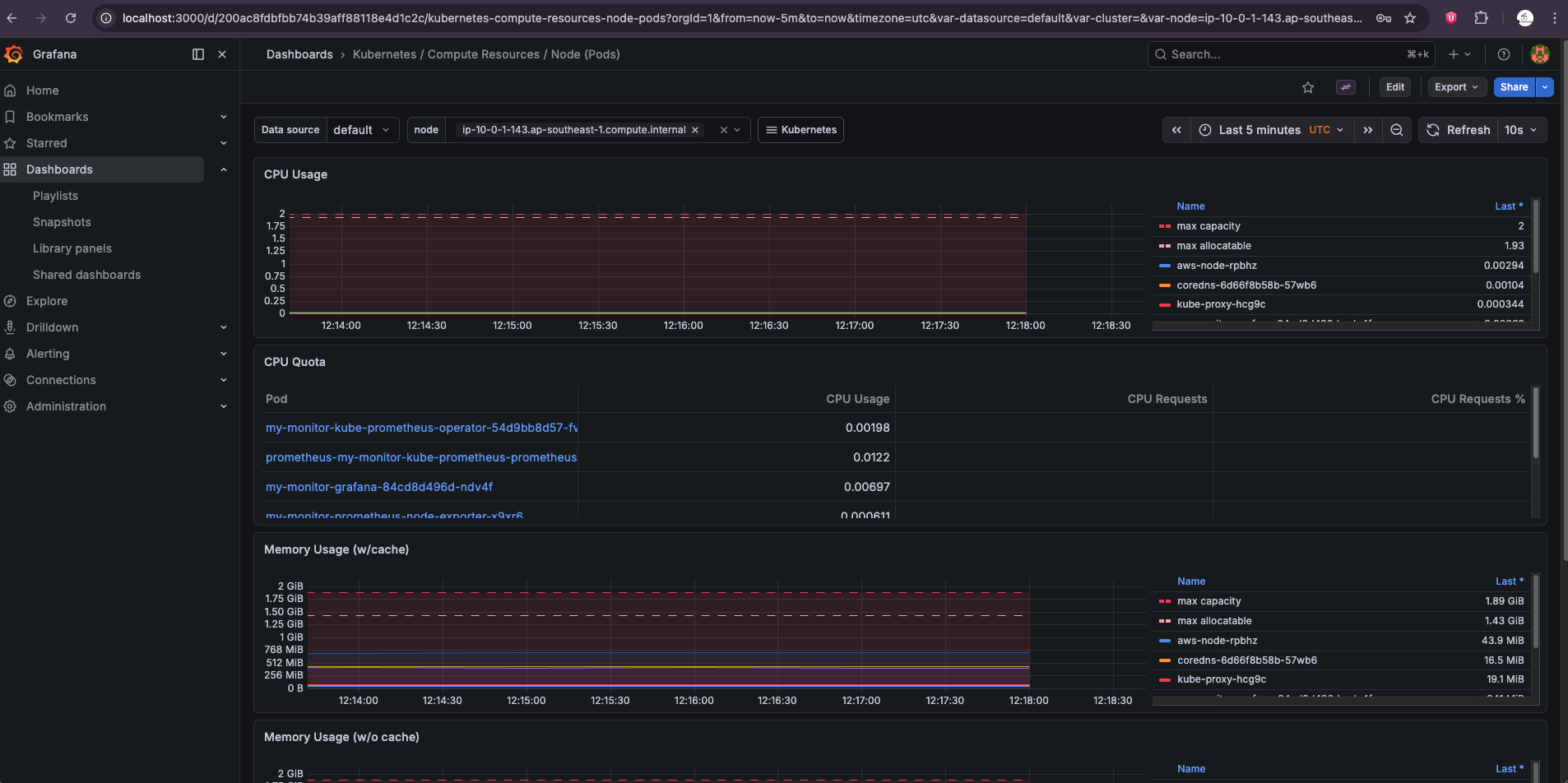
🕵️ Prometheus đang trốn ở đâu?
Trong cụm EKS của bro, Prometheus đang chạy dưới dạng một cái Service thầm lặng trong namespace monitoring. Bro có thể tìm thấy "hành tung" của nó bằng lệnh này:
kubectl get svc -n monitoring
👉 Bro sẽ thấy một cái Service có tên đại loại là my-monitor-kube-prometheus-prometheus. Nó thường chạy ở cổng 9090.
🚀 Cách "đột nhập" vào Tổng hành dinh Prometheus
Nếu bro muốn tận mắt nhìn thấy "bộ não" này đang hoạt động ra sao (không qua trung gian Grafana), hãy dùng lại chiêu thức "đục đường hầm":
Bước 1: Mở cổng vào Prometheus (Mở một Tab Terminal mới trên máy Mac):
kubectl port-forward svc/my-monitor-kube-prometheus-prometheus 9090:9090 -n monitoring
Bước 2: Truy cập giao diện "đồ cổ" Mở trình duyệt và gõ: http://localhost:9090 👉 Đừng sốc nhé! Giao diện của Prometheus cực kỳ đơn giản, đậm chất kỹ thuật, không màu mè như Grafana đâu.
🎯 2 Thứ "Đáng đồng tiền bát gạo" nhất trong Prometheus UI
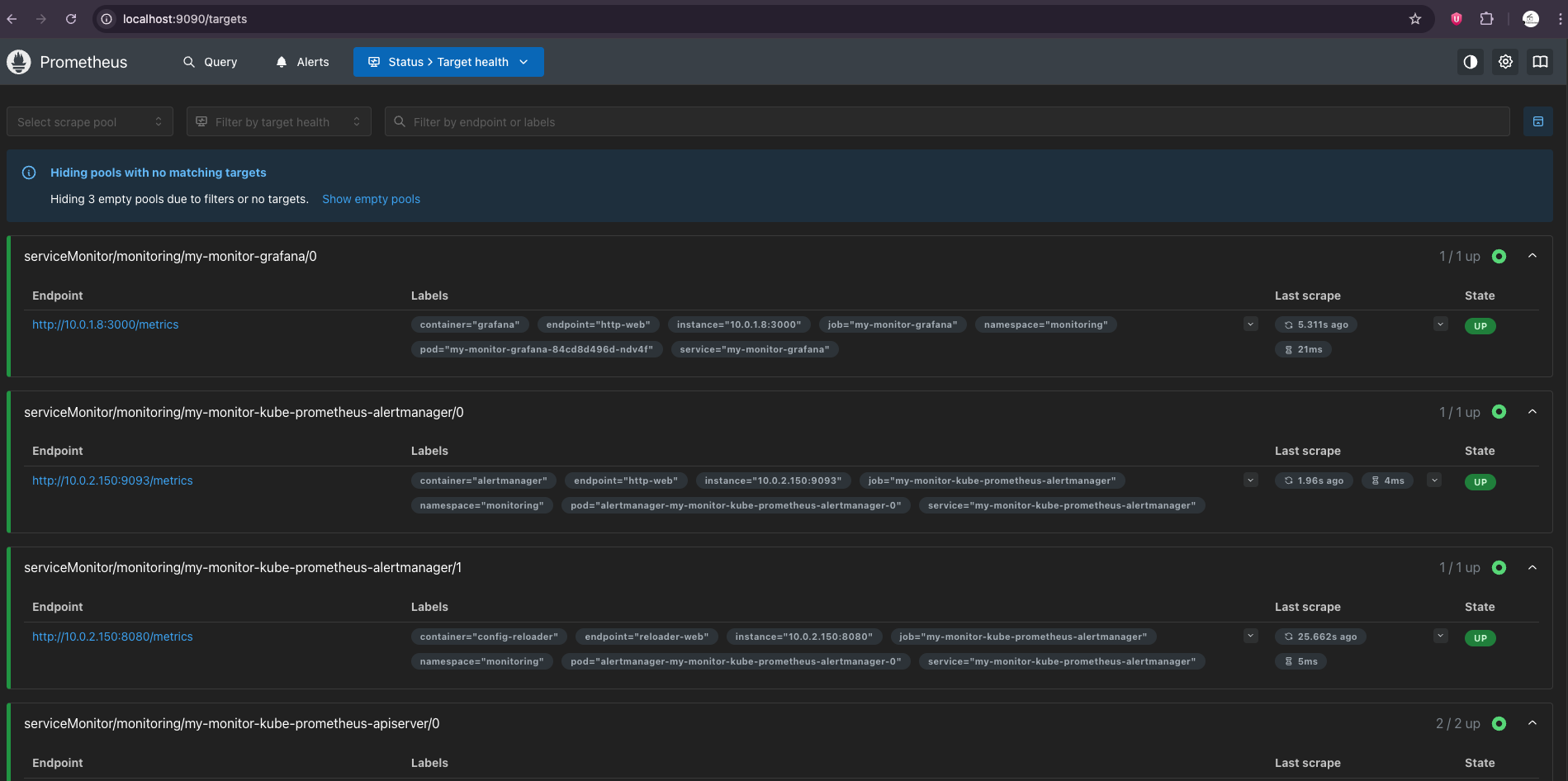
Khi đã vào được localhost:9090, Bạn hãy xem 2 chỗ này để thấy mình thực sự là "ông trùm" hạ tầng:
-
Status -> Targets: Đây là danh sách những "con mồi" mà Prometheus đang đi hút dữ liệu. Bro nhìn xem có dòng nào báo
UPmàu xanh không? Nếu thấynode-exporterhaykubelethiện màu xanh, nghĩa là Prometheus đang "ăn" dữ liệu rất tốt. -
Ô tìm kiếm (Expression): Thử gõ một câu lệnh "thần chú" (PromQL) vào đây rồi nhấn Execute:
node_memory_Active_bytes👉 Nó sẽ hiện ra con số chính xác đến từng byte lượng RAM đang hoạt động trên cont3.mediumcủa bro. Grafana lấy dữ liệu từ chính chỗ này để vẽ biểu đồ đấy!
💡 Tóm tắt mối quan hệ "Cộng sinh"
-
Prometheus: Đi gom dữ liệu từ OriShop -> Lưu vào database riêng của nó.
-
Grafana: "Mượn" dữ liệu từ Prometheus -> Vẽ thành biểu đồ màu mè cho bro xem.
Kết luận
Triển khai Observability trên AWS EKS là bước đi quan trọng để tiến tới vận hành hệ thống chuyên nghiệp. Hy vọng qua bài viết này, bạn không chỉ biết cách cài đặt công cụ mà còn hiểu rõ các giới hạn vật lý của hạ tầng Cloud để có những quyết định nâng cấp đúng đắn.