
Ansible: Cài Đặt Hadoop Cluster Trên Ubuntu 22.04

Triển khai Hadoop Eco System theo cách thủ công trên nhiều server thường tiêu tốn hàng giờ đồng hồ với hàng loạt thao tác lặp đi lặp lại. Để tối ưu hóa quá trình này, bài viết dưới đây sẽ chia sẻ kịch bản Ansible hoàn chỉnh để thiết lập cụm Hadoop Cluster phiên bản 3.3.4 trên Ubuntu Server 22.04.
Thay vì gộp chung, kịch bản được chia nhỏ thành 5 Playbook theo đúng trình tự vòng đời cấu hình. Điều này giúp bạn dễ dàng theo dõi, debug và tái sử dụng cho các hệ thống lớn hơn.
1. Yêu Cầu Chuẩn Bị (Prerequisites)
-
Hệ điều hành: 2 máy chủ VPS chạy Ubuntu Server 22.04 (1 Master, 1 Slave).
-
Truy cập: Có quyền
rootthông qua SSH Key. Và nhớ là không đặt password cho SSH key nhé, tham khảo bài sau để setup SSH Key -
Máy điều khiển (Control Node): Đã cài đặt Ansible.
Đầu tiên, tạo file hosts.ini để khai báo danh sách IP. Lưu ý thêm tham số bỏ qua kiểm tra Host Key để Ansible chạy mượt mà không bị kẹt ở bước xác thực ban đầu:
[master]
103.221.220.187 ansible_user=root ansible_ssh_private_key_file=~/.ssh/your_ssh_key ansible_ssh_common_args='-o StrictHostKeyChecking=no'
[slaves]
116.118.51.126 ansible_user=root ansible_ssh_private_key_file=~/.ssh/your_ssh_key ansible_ssh_common_args='-o StrictHostKeyChecking=no'
[hadoop_cluster:children]
master
slaves
2. Kịch Bản Tự Động Hóa 5 Bước Bằng Ansible
Bước 1: Định danh hệ thống và file hosts
Các node cần được đổi hostname và cấu hình /etc/hosts để giao tiếp bằng tên miền nội bộ.
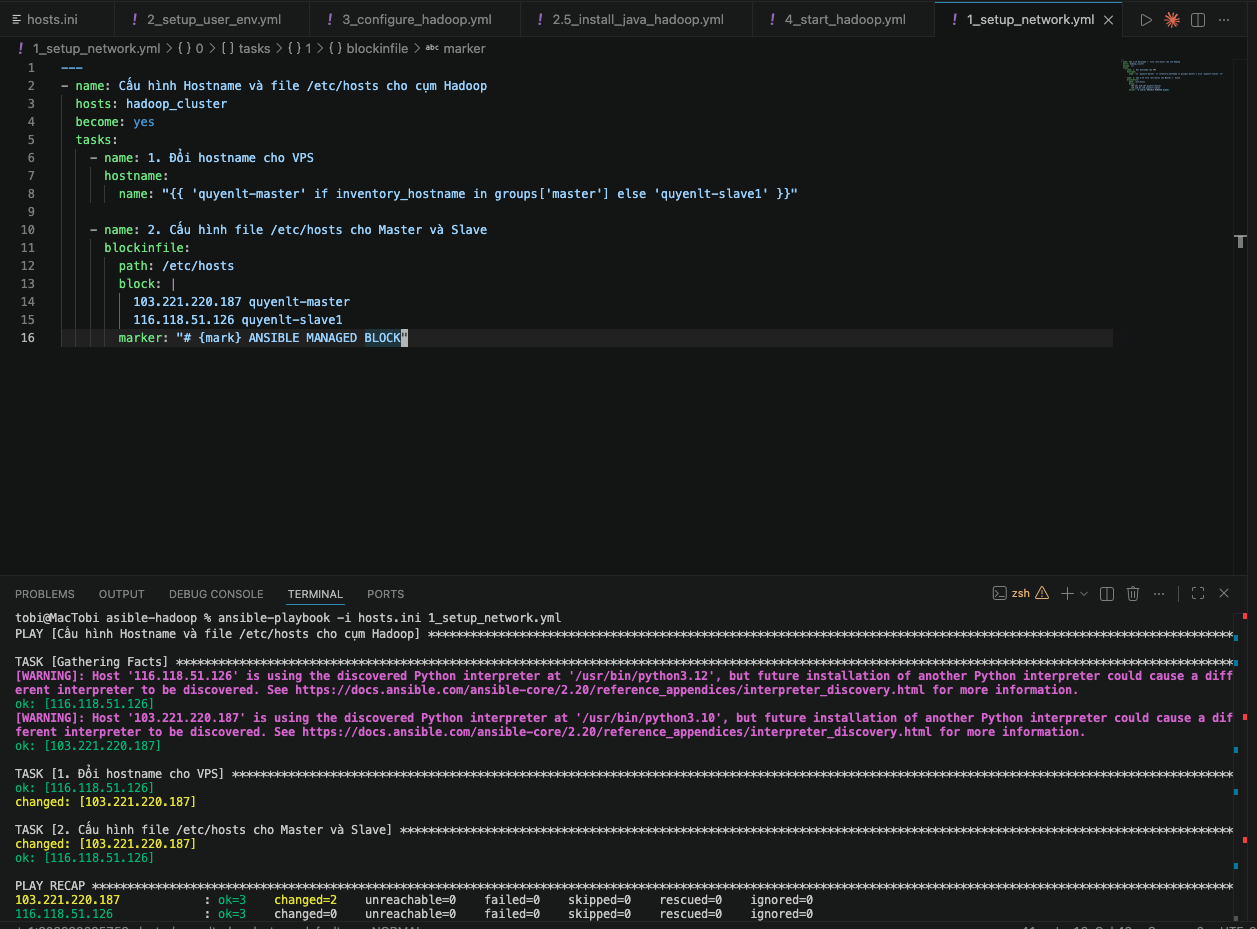
Tạo file 1_setup_network.yml:
---
- name: Cấu hình Hostname và file /etc/hosts cho cụm Hadoop
hosts: hadoop_cluster
become: yes
tasks:
- name: 1. Đổi hostname cho VPS
hostname:
name: "{{ 'quyenlt-master' if inventory_hostname in groups['master'] else 'quyenlt-slave1' }}"
- name: 2. Cấu hình file /etc/hosts cho Master và Slave
blockinfile:
path: /etc/hosts
block: |
103.221.220.187 quyenlt-master
116.118.51.126 quyenlt-slave1
marker: "# {mark} ANSIBLE MANAGED BLOCK"
Cách chạy: Bạn chạy playbook trên bằng lệnh:
ansible-playbook -i hosts.ini 1_setup_network.yml
Bước 2: Khởi tạo User và kết nối SSH Keyless
Hadoop cần chạy dưới một user riêng (hadoopquyenlt). Đồng thời, thiết lập SSH Key không mật khẩu giúp Master tự động điều phối các Slave .
Tạo file 2_setup_user_env.yml:
---
- name: Tạo user và cấu hình biến môi trường Hadoop
hosts: hadoop_cluster
become: yes
tasks:
- name: 1. Tạo user hadoopquyenlt
user:
name: hadoopquyenlt
shell: /bin/bash
create_home: yes
- name: 2. Thêm biến môi trường vào ~/.bashrc
blockinfile:
path: /home/hadoopquyenlt/.bashrc
create: yes
owner: hadoopquyenlt
group: hadoopquyenlt
block: |
export JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64
export HADOOP_HOME=/home/hadoopquyenlt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
marker: "# {mark} ANSIBLE HADOOP ENV"
- name: Thiết lập SSH Key không mật khẩu cho hadoopquyenlt
hosts: hadoop_cluster
become: yes
become_user: hadoopquyenlt
tasks:
- name: 3. Tạo SSH key
command: ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
args:
creates: ~/.ssh/id_rsa
- name: 4. Lấy Public Key của từng node
slurp:
src: /home/hadoopquyenlt/.ssh/id_rsa.pub
register: node_pub_key
- name: Phân phối Public Key của Master xuống các node
hosts: hadoop_cluster
become: yes
become_user: hadoopquyenlt
tasks:
- name: 5. Lưu Public Key của Master vào authorized_keys
authorized_key:
user: hadoopquyenlt
state: present
key: "{{ hostvars[item]['node_pub_key']['content'] | b64decode }}"
loop: "{{ groups['master'] }}"
Cách chạy: Bạn chạy playbook trên bằng lệnh:
ansible-playbook -i hosts.ini 2_setup_user_env.yml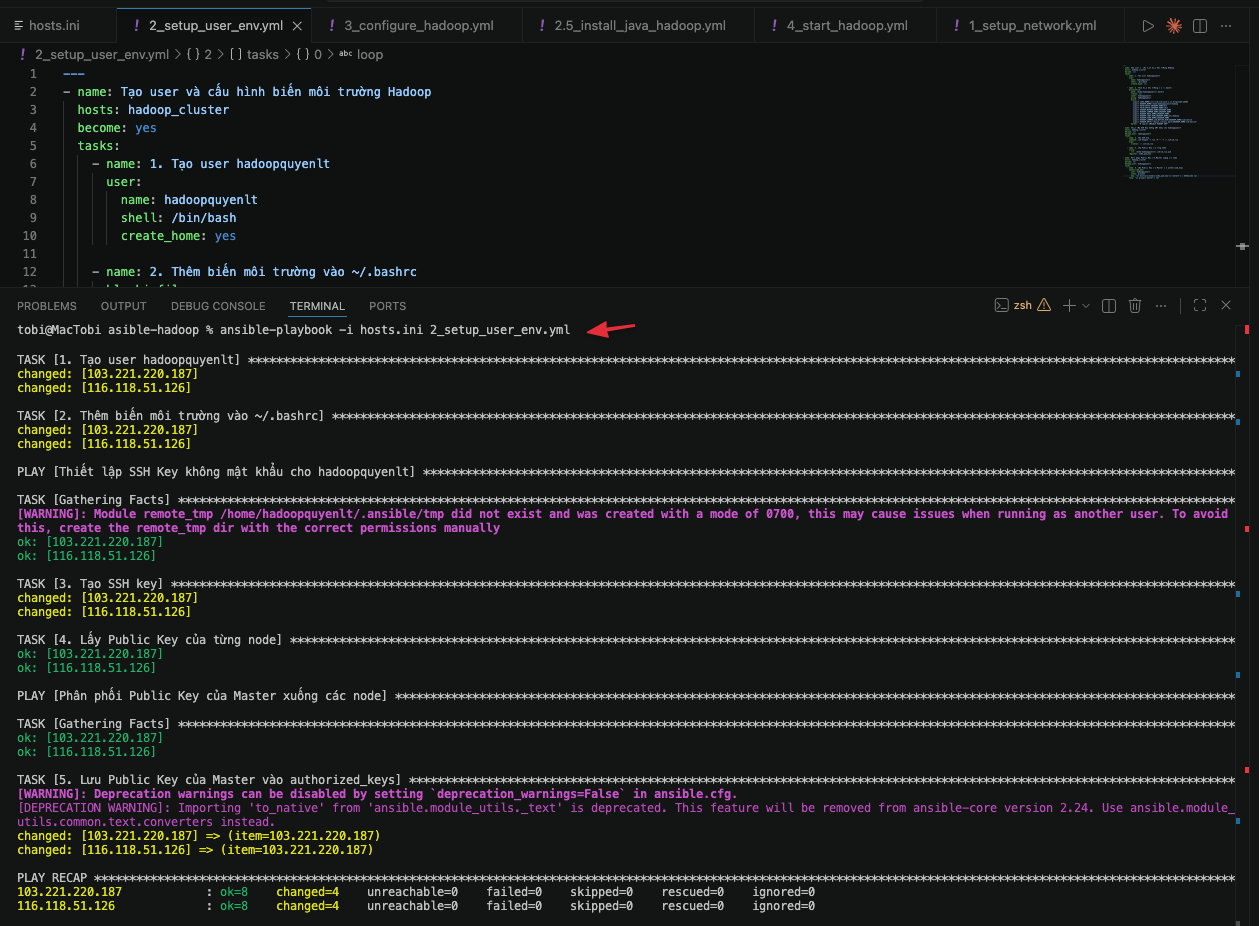
Bước 3: Cài đặt OpenJDK 11 và tải Hadoop 3.3.4
Tải trực tiếp mã nguồn Hadoop, giải nén và phân quyền .
Tạo file 2.5_install_java_hadoop.yml:
---
- name: Cài đặt Java và Hadoop 3.3.4
hosts: hadoop_cluster
become: yes
tasks:
- name: 1. Cập nhật apt cache
apt:
update_cache: yes
- name: 2. Cài đặt OpenJDK 11
apt:
name: openjdk-11-jdk
state: present
- name: 3. Cài đặt wget và tar (nếu chưa có)
apt:
name:
- wget
- tar
state: present
- name: 4. Tải và giải nén Hadoop 3.3.4
unarchive:
src: https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
dest: /home/hadoopquyenlt/
remote_src: yes
creates: /home/hadoopquyenlt/hadoop-3.3.4
- name: 5. Đổi tên thư mục thành hadoop
command: mv /home/hadoopquyenlt/hadoop-3.3.4 /home/hadoopquyenlt/hadoop
args:
creates: /home/hadoopquyenlt/hadoop
- name: 6. Phân quyền sở hữu toàn bộ thư mục cho user hadoopquyenlt
file:
path: /home/hadoopquyenlt/hadoop
state: directory
owner: hadoopquyenlt
group: hadoopquyenlt
recurse: yes
Cách chạy: Bạn chạy playbook trên bằng lệnh:
ansible-playbook -i hosts.ini 2.5_install_java_hadoop.yml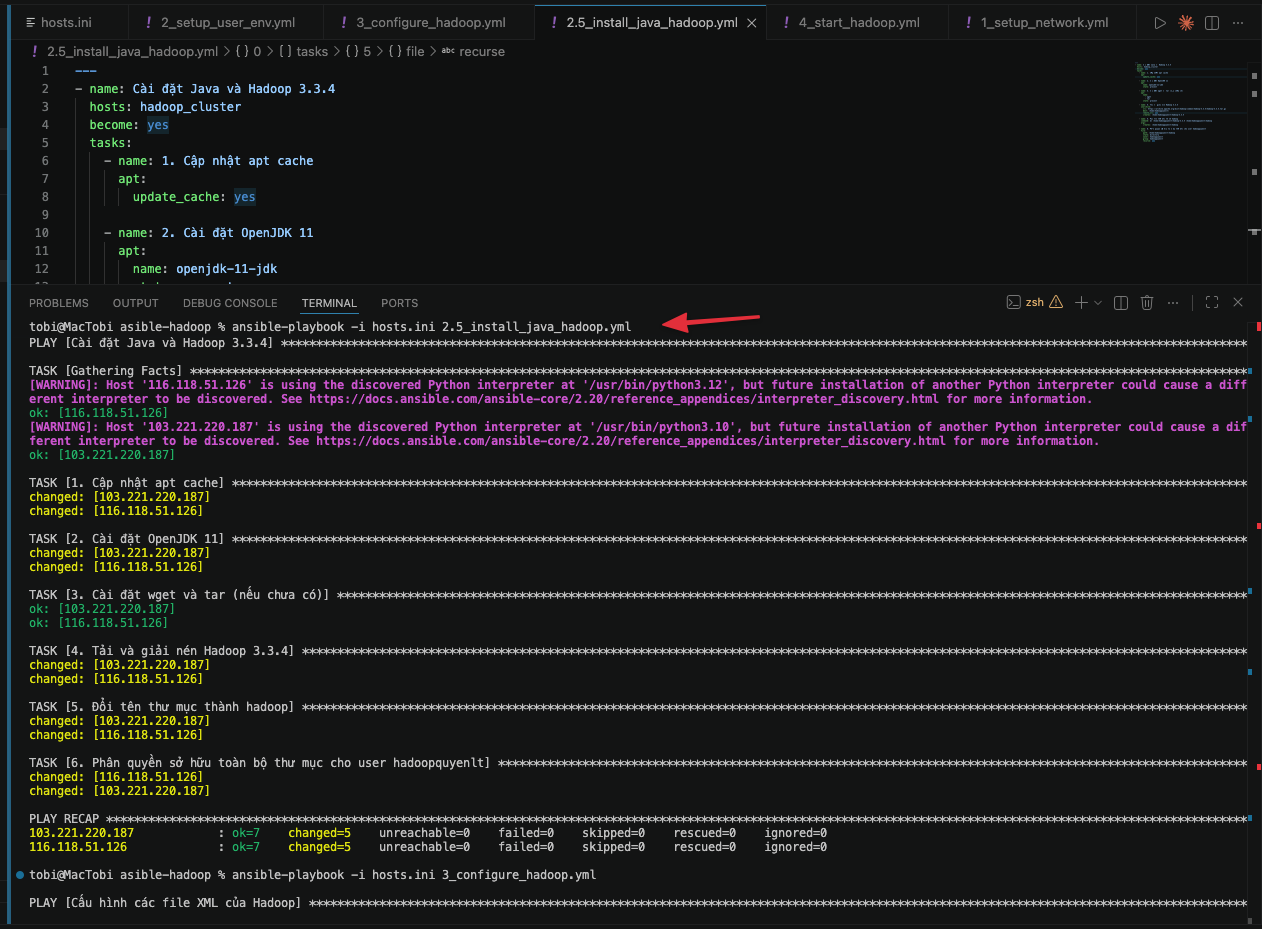
Bước 4: Đổ cấu hình XML lõi
Bước này ghi toàn bộ thông số hạ tầng vào các file config HDFS, YARN và MapReduce .
Tạo file 3_configure_hadoop.yml:
---
- name: Cấu hình các file XML của Hadoop
hosts: hadoop_cluster
become: yes
become_user: hadoopquyenlt
vars:
hadoop_conf_dir: /home/hadoopquyenlt/hadoop/etc/hadoop
tasks:
- name: 1. Đảm bảo thư mục tmp tồn tại với quyền 777
file:
path: /home/hadoopquyenlt/tmp
state: directory
mode: '0777'
- name: 2. Cấu hình hadoop-env.sh
lineinfile:
path: "{{ hadoop_conf_dir }}/hadoop-env.sh"
regexp: '^#?\s*export JAVA_HOME='
line: 'export JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64'
- name: 3. Cấu hình core-site.xml
copy:
dest: "{{ hadoop_conf_dir }}/core-site.xml"
content: |
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoopquyenlt/tmp</value>
<description>Temporary Directory.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://quyenlt-master:9000</value>
<description>Use HDFS as file storage engine</description>
</property>
</configuration>
- name: 4. Cấu hình hdfs-site.xml
copy:
dest: "{{ hadoop_conf_dir }}/hdfs-site.xml"
content: |
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>Default block replication.</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoopquyenlt/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoopquyenlt/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
- name: 5. Cấu hình yarn-site.xml
copy:
dest: "{{ hadoop_conf_dir }}/yarn-site.xml"
content: |
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>quyenlt-master:9002</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>quyenlt-master:9003</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>quyenlt-master:9004</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>quyenlt-master:9005</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>quyenlt-master:9006</value>
</property>
</configuration>
- name: Cấu hình các file dành riêng cho Master
hosts: master
become: yes
become_user: hadoopquyenlt
vars:
hadoop_conf_dir: /home/hadoopquyenlt/hadoop/etc/hadoop
tasks:
- name: 6. Cấu hình mapred-site.xml
copy:
dest: "{{ hadoop_conf_dir }}/mapred-site.xml"
content: |
<configuration>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>quyenlt-master:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoopquyenlt/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoopquyenlt/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoopquyenlt/hadoop</value>
</property>
</configuration>
- name: 7. Khai báo các máy slave vào file workers
copy:
dest: "{{ hadoop_conf_dir }}/workers"
content: |
quyenlt-slave1
Cách chạy: Bạn chạy playbook trên bằng lệnh:
ansible-playbook -i hosts.ini 3_configure_hadoop.yml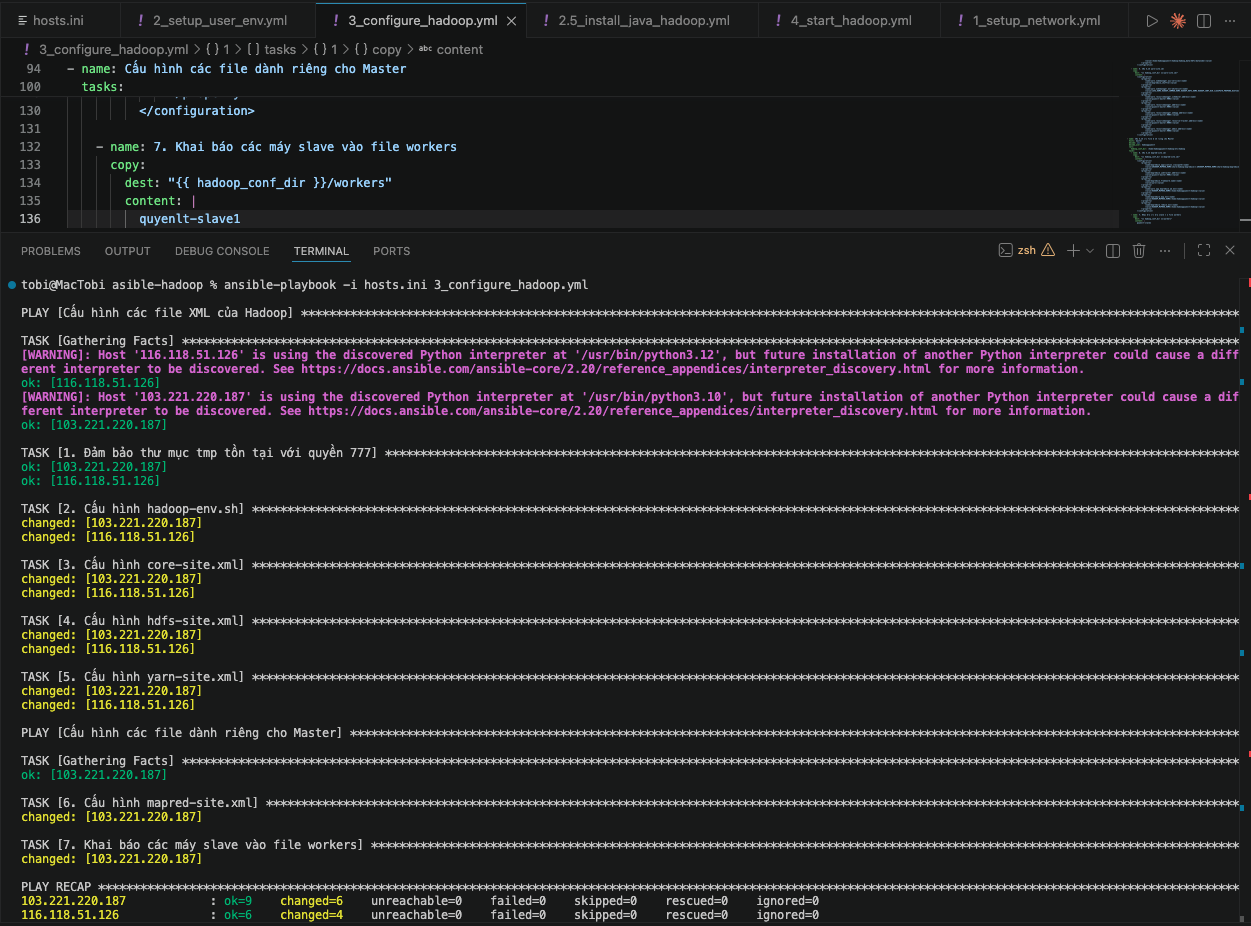
Bước 5: Format NameNode và Khởi Động Hệ Thống
Playbook này sử dụng đường dẫn tuyệt đối để tránh lỗi command not found khi chạy ở chế độ non-interactive shell.
Tạo file 4_start_hadoop.yml:
---
- name: Khởi tạo và chạy Hadoop Cluster
hosts: master
become: yes
become_user: hadoopquyenlt
vars:
hadoop_home: /home/hadoopquyenlt/hadoop
java_home: /usr/lib/jvm/java-1.11.0-openjdk-amd64
tasks:
- name: 1. Format NameNode (Chỉ chạy 1 lần)
command: "{{ hadoop_home }}/bin/hdfs namenode -format"
args:
creates: "{{ hadoop_home }}/hadoop_data/hdfs/namenode/current"
- name: 2. Khởi động Hadoop (start-all.sh)
command: "{{ hadoop_home }}/sbin/start-all.sh"
environment:
JAVA_HOME: "{{ java_home }}"
HADOOP_HOME: "{{ hadoop_home }}"
- name: 3. Kiểm tra các tiến trình (jps) trên Master
command: "{{ java_home }}/bin/jps"
register: master_jps
- name: Hiển thị kết quả JPS của Master
debug:
msg: "{{ master_jps.stdout_lines }}"
- name: Kiểm tra tiến trình trên Slave
hosts: slaves
become: yes
become_user: hadoopquyenlt
vars:
java_home: /usr/lib/jvm/java-1.11.0-openjdk-amd64
tasks:
- name: 4. Kiểm tra các tiến trình (jps) trên Slave
command: "{{ java_home }}/bin/jps"
register: slave_jps
- name: Hiển thị kết quả JPS của Slave
debug:
msg: "{{ slave_jps.stdout_lines }}"
Cách chạy: Bạn chạy playbook trên bằng lệnh:
ansible-playbook -i hosts.ini 4_start_hadoop.yml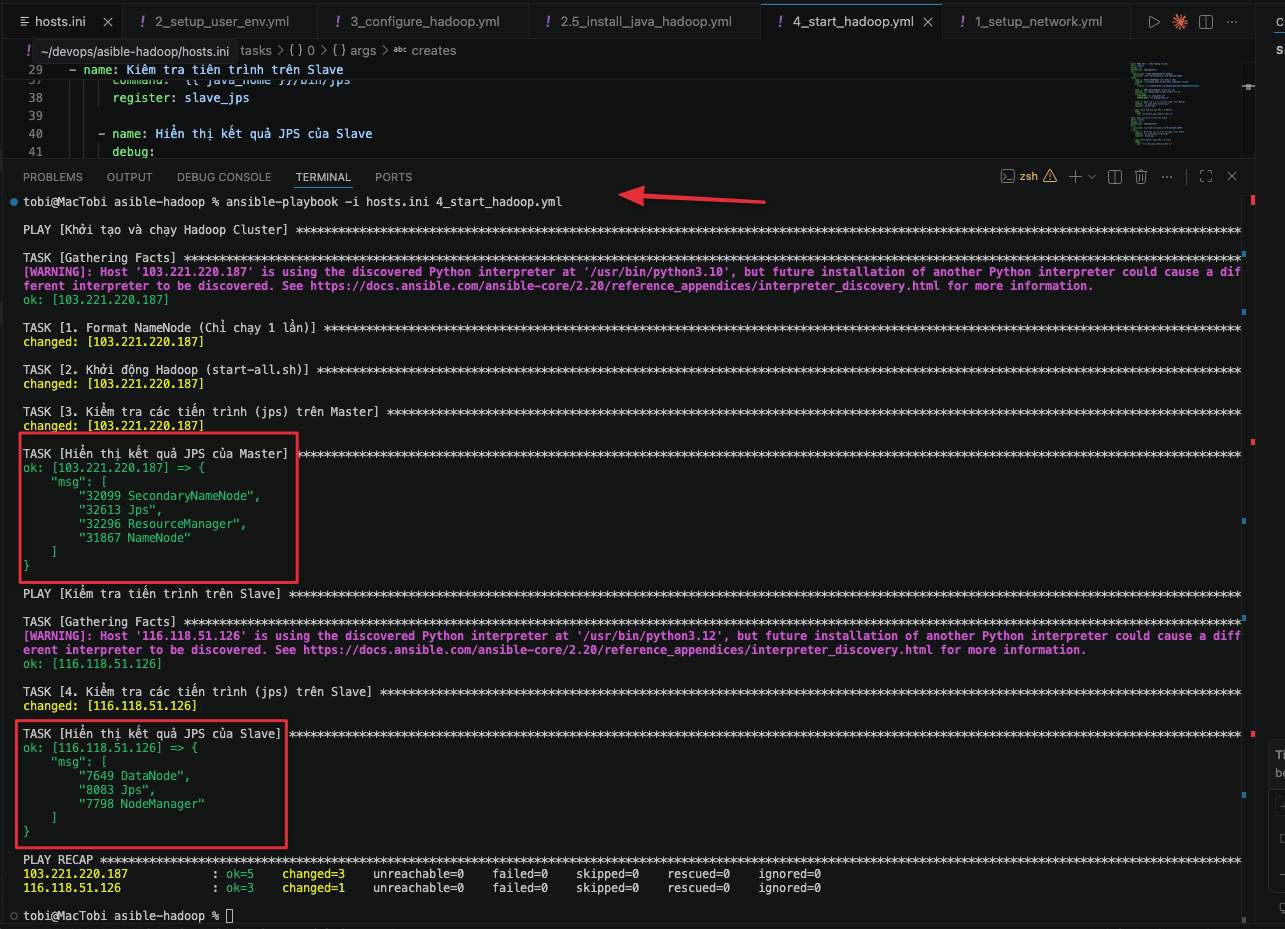
3. Nghiệm Thu & Kiểm Thử (WordCount Job)
Sau khi cụm Hadoop đã chạy, hãy xác minh HDFS và MapReduce bằng thuật toán đếm từ. Đăng nhập vào máy Master dưới quyền user hadoopquyenlt, tạo file test.sh với nội dung bên dưới :
#!/bin/bash
# test the hadoop cluster by running wordcount
# create input files
mkdir input
echo "Hello World" >input/file1.txt
echo "Hello Hadoop" >input/file2.txt
# create input directory on HDFS
hadoop fs -mkdir -p input1
# put input files to HDFS
hdfs dfs -put ./input/* input1
# run wordcount
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-3.3.4-sources.jar org.apache.hadoop.examples.WordCount input1 output1
# print the input files
echo -e "\ninput file1.txt:"
hdfs dfs -cat input1/file1.txt
echo -e "\ninput file2.txt:"
hdfs dfs -cat input1/file2.txt
# print the output of wordcount
echo -e "\nwordcount output:"
hdfs dfs -cat output1/part-r-00000
Cấp quyền và chạy :
chmod +x test.sh
./test.sh
Nếu kết quả màn hình in ra số đếm như Hadoop 1, Hello 2, World 1 , thì xin chúc mừng, cụm Hadoop đã được tự động hóa cài đặt hoàn hảo
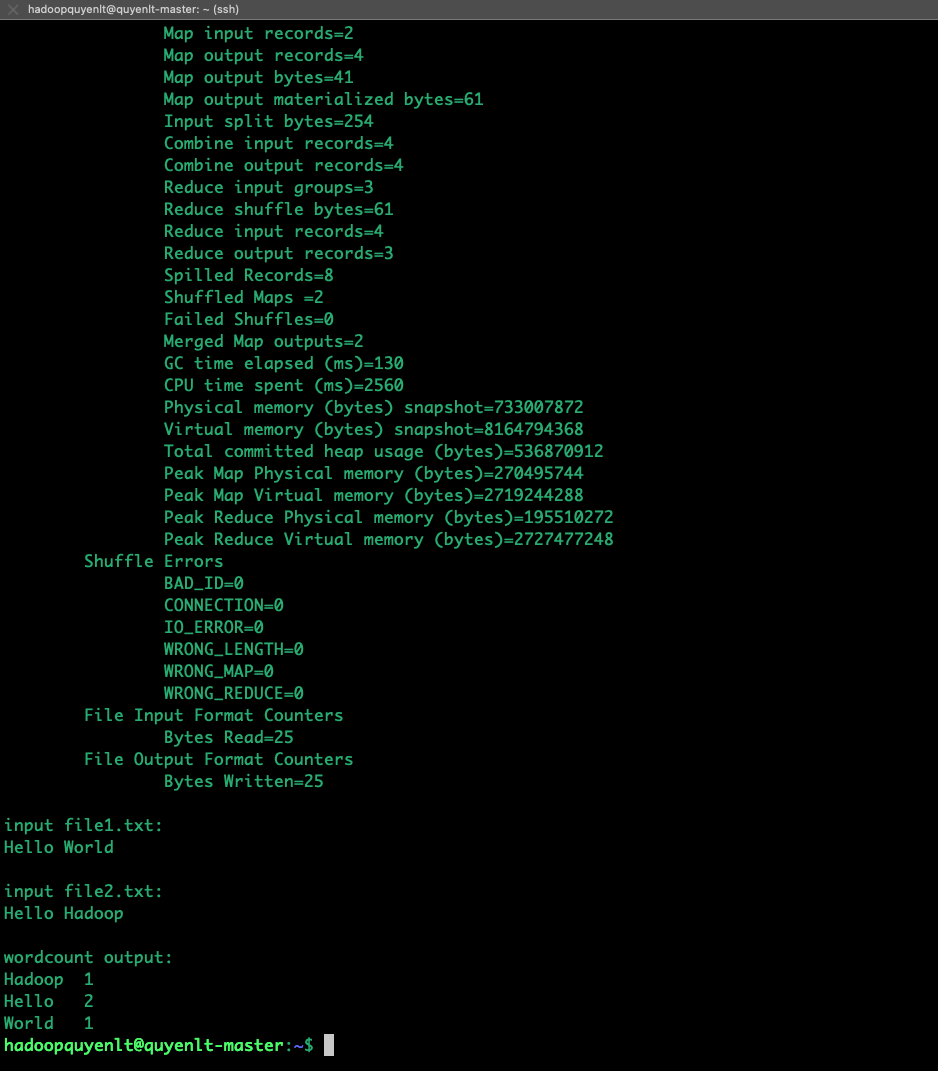
Trong trường hợp bạn muốn test lại thì phải xóa kết quả cũ bằng lệnh sau :
rm -rf input
hadoop fs -rm -r input1
hadoop fs -rm -r output1#rồi chạy lại lệnh
./test.sh
Một số lưu ý:
- Lệnh “hadoop namenode -format” chỉ thực hiện một lần duy nhất lúc cài hadoop. Nếu nchạy lại lần 2 thì cả cụm (cluster) bị mất.
- Nếu chỉ muốn làm sạch datanode thì dùng ssh đến node đó, sau đó có thể format data disk hoặc xóa dữ liệu. Cách an toàn hơn là chạy lệnh “rm -rf /data/disk1”, “rm -rf/data/disk2”, giả sử datanode lưu trữ dữ liệu tại /data/disk1 và /data/disk2.
Tạo file test.sh với nội dung bên dưới nếu bạn dùng hadoop 3.4 nhé :
#!/bin/bash# Script test cụm Hadoop bằng bài toán WordCount (Hỗ trợ chạy nhiều lần)echo "=== 1. DỌN DẸP DỮ LIỆU CŨ TRƯỚC KHI CHẠY ==="# Xóa thư mục local cũ để tạo mớirm -rf input# Ép buộc xóa thư mục input và output trên HDFS từ các lần chạy trước (nếu có)hdfs dfs -rm -r -f input1hdfs dfs -rm -r -f output1echo "=== 2. TẠO VÀ TẢI DỮ LIỆU LÊN HDFS ==="# Tạo dữ liệu mẫu ở localmkdir inputecho "Hello World" > input/file1.txtecho "Hello Hadoop" > input/file2.txt# Tạo thư mục trên HDFS và đẩy dữ liệu lênhadoop fs -mkdir -p input1hdfs dfs -put ./input/* input1echo "=== 3. CHẠY MAPREDUCE WORDCOUNT ==="# Sử dụng yarn jar và trỏ đúng file thực thi của bản Hadoop 3.4.3 (không dùng file -sources.jar)yarn jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.3.jar wordcount input1 output1echo "=== 4. HIỂN THỊ KẾT QUẢ ĐẦU VÀO ==="echo -e "\ninput file1.txt:"hdfs dfs -cat input1/file1.txtecho -e "\ninput file2.txt:"hdfs dfs -cat input1/file2.txtecho "=== 5. HIỂN THỊ KẾT QUẢ MAPREDUCE ==="echo -e "\nwordcount output:"hdfs dfs -cat output1/part-r-00000
Lời kết: Ứng dụng Infrastructure as Code (IaC) với Ansible vào triển khai Hadoop giúp hệ thống đạt độ ổn định cao và cực kỳ dễ dàng khi cần cấu hình lại. Hy vọng kịch bản 5 bước trên sẽ hỗ trợ đắc lực cho các bài toán xử lý Big Data của bạn!