

Cài Đặt Hadoop Single Node Cluster trên Ubuntu 24.04

Apache Hadoop là gì?
Apache Hadoop là một framework mã nguồn mở (open-source) được phát triển bởi Apache Software Foundation, cho phép lưu trữ và xử lý các tập dữ liệu cực lớn (Big Data) trong môi trường phân tán. Thay vì dựa vào một siêu máy tính đắt tiền, Hadoop cho phép chạy ứng dụng trên các cụm (cluster) gồm hàng nghìn máy tính phổ thông (commodity hardware) được kết nối với nhau.
Sức mạnh cốt lõi của Hadoop nằm ở khả năng chia nhỏ một tác vụ khổng lồ thành nhiều tác vụ nhỏ và xử lý song song trên nhiều máy tính cùng lúc.
Kiến trúc cốt lõi của Hadoop (Hadoop Core)
Trong phiên bản Hadoop 3.x mà chúng ta cài đặt, hệ thống bao gồm 3 thành phần chính hoạt động như "kiềng ba chân":
-
HDFS (Hadoop Distributed File System):
-
Đóng vai trò là lớp lưu trữ.
-
Dữ liệu khi nạp vào HDFS sẽ được chia nhỏ thành các khối (Block) và phân tán ra các máy khác nhau.
-
Cơ chế Replication (nhân bản): Mỗi khối dữ liệu được sao chép ra nhiều bản (mặc định là 3) để nếu một máy bị hỏng, dữ liệu vẫn an toàn ở máy khác. Trong bài lab này, vì chạy chế độ Single Node (1 máy), chúng ta cấu hình
dfs.replicationlà 1.
-
-
MapReduce:
-
Đóng vai trò là lớp xử lý.
-
Đây là mô hình lập trình giúp tính toán dữ liệu song song. Nó gồm hai bước: Map (chia nhỏ, sơ chế dữ liệu) và Reduce (tổng hợp kết quả). Ví dụ chúng ta chạy lệnh
greptrong bài lab chính là một ứng dụng của MapReduce.
-
-
YARN (Yet Another Resource Negotiator):
-
Đóng vai trò là lớp quản lý tài nguyên.
-
YARN giống như "hệ điều hành" của cluster. Nó chịu trách nhiệm cấp phát RAM, CPU cho các ứng dụng chạy trên hệ thống.
-
YARN bao gồm ResourceManager (quản lý chung) và NodeManager (quản lý từng máy trạm).
-
Tại sao nên sử dụng Hadoop?
-
Chi phí thấp: Chạy tốt trên phần cứng giá rẻ, không cần máy chủ chuyên dụng đắt tiền.
-
Khả năng mở rộng (Scalability): Có thể dễ dàng thêm máy mới vào cluster để tăng dung lượng lưu trữ và tốc độ xử lý mà không cần dừng hệ thống.
-
Chịu lỗi tốt (Fault Tolerance): Nhờ cơ chế nhân bản dữ liệu của HDFS, hệ thống vẫn hoạt động bình thường ngay cả khi có máy bị cháy hỏng.
Bài hướng dẫn này không chỉ cung cấp các câu lệnh chuẩn mà còn chỉ ra những lỗi thường gặp (như sai phiên bản Java, lỗi file cấu hình XML, lỗi đường dẫn JAR) mà chính mình đã đúc kết được sau quá trình thực hành.
1. Chuẩn bị môi trường
Trước khi cài Hadoop, chúng ta cần cài đặt Java (JDK) và SSH.
Bước 1.1: Cập nhật hệ thống và cài Java
Hadoop 3.x yêu cầu Java 8 trở lên. Trên Ubuntu 24.04, chúng ta sẽ sử dụng OpenJDK 21.
sudo apt update && sudo apt upgrade -y
sudo apt install default-jdk -y
Kiểm tra phiên bản Java sau khi cài:
java -version
Kết quả kỳ vọng: openjdk version "21.0..."
Bước 1.2: Tạo User riêng cho Hadoop
Để quản lý quyền hạn và bảo mật tốt hơn, bạn nên tạo một user riêng (ví dụ: hadoopquyenlt hoặc hadoopuser).
sudo adduser hadoopquyenlt
# Nhập mật khẩu và thông tin user
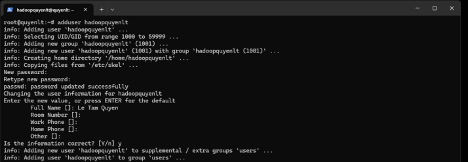
Thêm user này vào nhóm sudo (nếu cần quyền quản trị):
sudo usermod -aG sudo hadoopquyenltSau đó, chuyển sang user mới để thực hiện các bước tiếp theo:
su - hadoopquyenlt
2. Cài đặt Hadoop 3.4.2
Bước 2.1: Tải và giải nén Hadoop
Truy cập trang chủ Apache hoặc dùng lệnh wget để tải bản 3.4.2 (Lưu ý: Link có thể thay đổi, nếu lỗi 404 hãy kiểm tra lại trang chủ Apache Hadoop).
cd ~
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.4.2/hadoop-3.4.2.tar.gzGiải nén và đổi tên thư mục cho gọn:
tar -xzf hadoop-3.4.2.tar.gz
mv hadoop-3.4.2 hadoop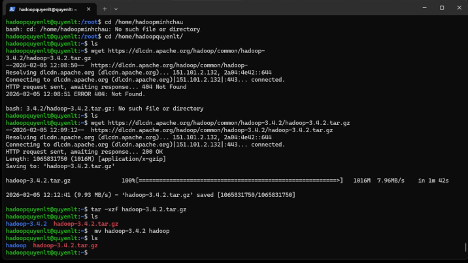
Bước 2.2: Cấu hình Biến môi trường
Đây là bước quan trọng nhất. Bạn cần trỏ đúng đường dẫn Java và Hadoop trong file .bashrc.
Mở file .bashrc:
vim ~/.bashrc
Thêm đoạn sau vào cuối file (Lưu ý: Đường dẫn Java 21 trên Ubuntu thường là /usr/lib/jvm/java-21-openjdk-amd64, hãy kiểm tra kỹ trên máy bạn):
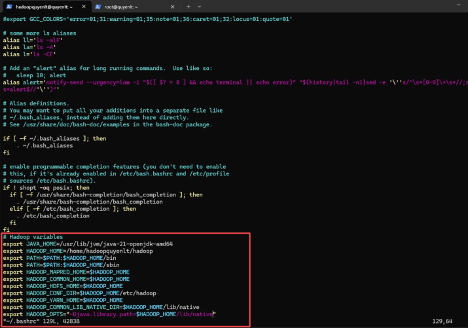
# Hadoop variables
export JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64
export HADOOP_HOME=/home/hadoopquyenlt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Cập nhật thay đổi:
source ~/.bashrc
Bước 2.3: Cấu hình hadoop-env.sh
Mở file cấu hình môi trường của Hadoop:
vim ~/hadoop/etc/hadoop/hadoop-env.sh
Tìm dòng export JAVA_HOME và sửa thành:
export JAVA_HOME=/usr/lib/jvm/java-1.21.0-openjdk-amd64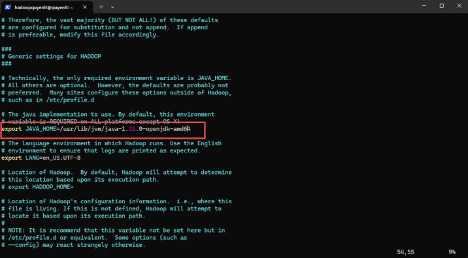
3. Cấu hình Hadoop (Pseudo-Distributed Mode)
Chúng ta sẽ cấu hình Hadoop chạy giả lập phân tán trên 1 máy (Single Node).
Bước 3.1: Cấu hình SSH (Passwordless Login)
Hadoop cần SSH vào localhost mà không cần mật khẩu.
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
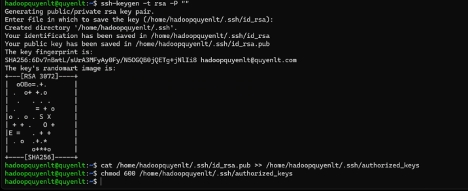
Thử SSH: ssh localhost (Nếu vào được mà không hỏi pass là thành công).
Bước 3.2: Sửa các file XML (Quan trọng)
Các file cấu hình nằm trong ~/hadoop/etc/hadoop/.
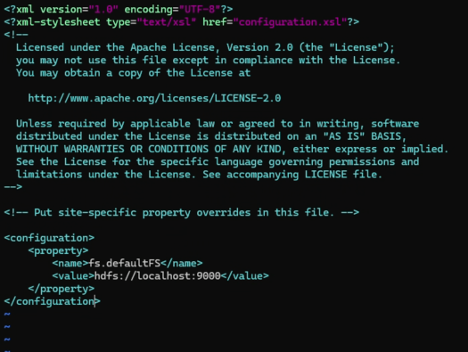
1. File core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
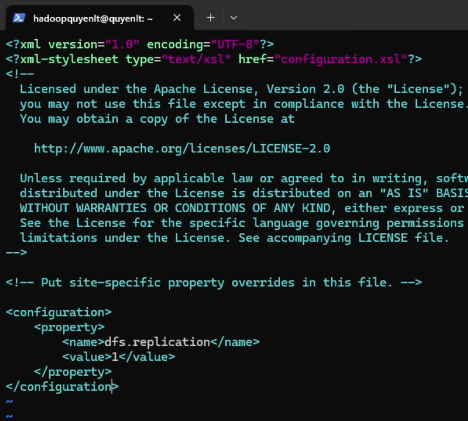
2. File hdfs-site.xml: Vì chạy 1 node nên set replication = 1.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3. File mapred-site.xml: Kích hoạt YARN framework.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
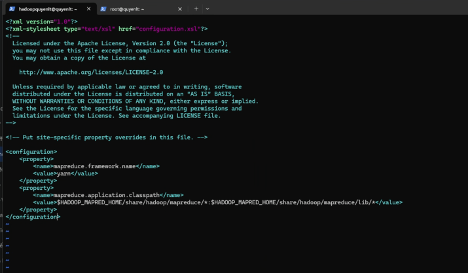
4. File yarn-site.xml: Lưu ý: Dòng yarn.nodemanager.env-whitelist rất dài, tuyệt đối không được tự ý xuống dòng (Enter) giữa chừng các giá trị.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>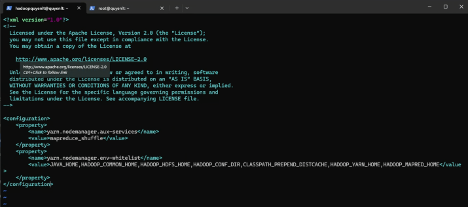
4. Khởi chạy hệ thống
Bước 4.1: Format NameNode
Chỉ chạy lệnh này một lần duy nhất khi cài đặt lần đầu.
hdfs namenode -format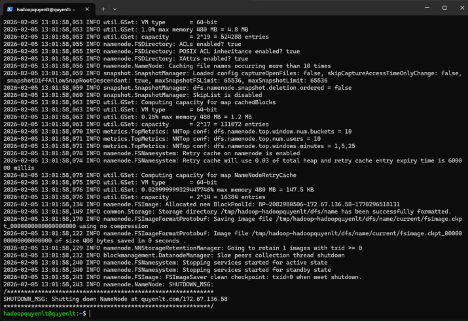
Bước 4.2: Start DFS và YARN
start-dfs.sh
start-yarn.shKiểm tra bằng lệnh jps. Nếu thành công, bạn phải thấy đủ 5 tiến trình: NameNode, DataNode, SecondaryNameNode, ResourceManager, NodeManager.
5. Chạy thử nghiệm MapReduce (Word Count)
Đây là bước để kiểm chứng hệ thống hoạt động đúng. Chúng ta sẽ dùng ví dụ grep có sẵn để tìm chuỗi ký tự trong các file xml.
Tạo thư mục trên HDFS:
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hadoopquyenlt
hdfs dfs -mkdir /user/hadoopquyenlt/input1Đẩy dữ liệu vào:
hdfs dfs -put ~/hadoop/etc/hadoop/*.xml /user/hadoopquyenlt/input1

Chạy MapReduce: Lưu ý: Kiểm tra kỹ phiên bản file jar trong thư mục share. Ở bản 3.4.2 file tên là hadoop-mapreduce-examples-3.4.2.jar (nhiều hướng dẫn cũ ghi là 3.3.4 sẽ gây lỗi).
hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.2.jar grep input1 output1 'dfs[a-z.]+'
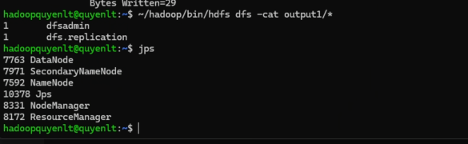
Xem kết quả:
hdfs dfs -cat output1/*
6. Các lỗi thường gặp (Troubleshooting)
Trong quá trình cài đặt, mình đã gặp và xử lý các lỗi sau, các bạn lưu ý nhé:
-
Lỗi "JAR does not exist":
-
Nguyên nhân: Copy lệnh trên mạng dùng phiên bản cũ (ví dụ 3.3.4) trong khi cài bản 3.4.2.
-
Khắc phục: Dùng lệnh
lsđể xem chính xác tên file trong thư mụcshare/hadoop/mapreduce/.
-
-
Lỗi Config XML bị sai cú pháp:
-
Nguyên nhân: Copy code từ file Word hoặc PDF bị dính ký tự xuống dòng (Newline) trong thẻ
<value>. -
Khắc phục: Đảm bảo các giá trị trong thẻ
<value>phải viết liền 1 dòng.
-
-
Lỗi dấu nháy đơn:
-
Khi copy lệnh, chú ý dấu
'(thẳng) khác với dấu’(cong/nghiêng). Linux chỉ hiểu dấu thẳng.
-
Kết luận
Vậy là chúng ta đã hoàn thành việc xây dựng một Single Node Hadoop Cluster trên Ubuntu 24.04. Đây là bước đệm quan trọng để bạn tiếp tục nghiên cứu sâu hơn về hệ sinh thái Big Data (Spark, Hive, Kafka...).
Nếu gặp khó khăn trong quá trình cài đặt, hãy để lại bình luận bên dưới nhé!