

Hadoop Ecosystem: Cài đặt, Cấu hình & Demo Apache Hive & HBase

Ở bài trước chúng ta đã xử lý dọn dẹp dữ liệu với Apache pig rồi, tiếp tới đây chúng ta sẽ sử dụng Apache Hive và Apache Hbase để truy vấn Data nhé. Cơ sở lý thuyết của nó bạn có thể xem ở đây.
1. CÀI ĐẶT VÀ CẤU HÌNH APACHE HIVE (DATA WAREHOUSE)
1.1. Tải và thiết lập thư mục
Tải phiên bản Apache Hive 4.2.0 từ kho lưu trữ chính thức và tiến hành giải nén, đổi tên thư mục để dễ quản lý:
cd /opt
sudo wget https://dlcdn.apache.org/hive/hive-4.2.0/apache-hive-4.2.0-bin.tar.gz
sudo tar -xzf apache-hive-4.2.0-bin.tar.gz
sudo mv apache-hive-4.2.0-bin hive
sudo chown -R hadoopnhom2:hadoopnhom2 /opt/hive
hive --version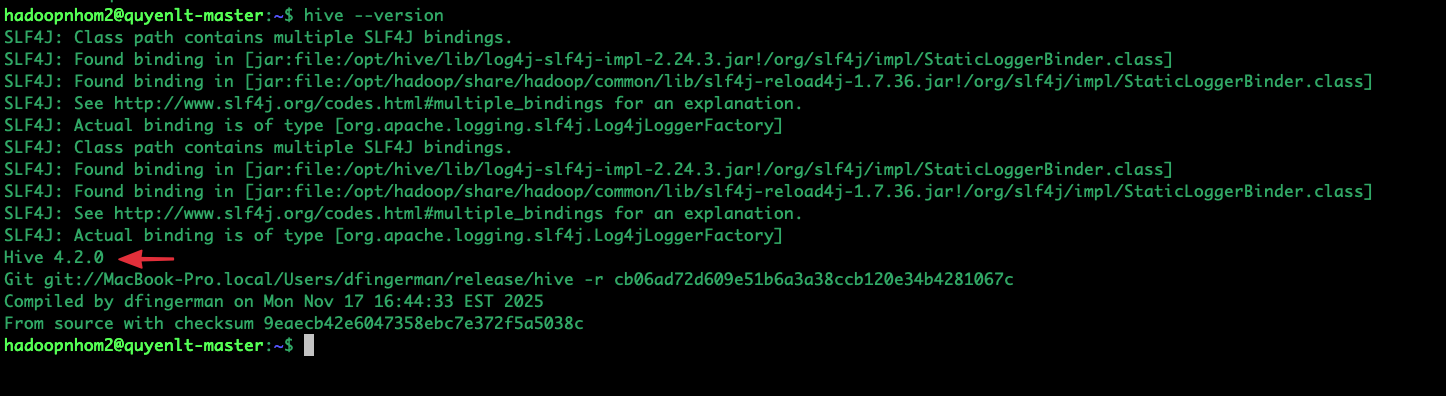
Thiết lập biến môi trường cho Hive bằng cách mở file ~/.bashrc:
nano ~/.bashrc
Thêm các dòng sau vào cuối file và nạp lại cấu hình:
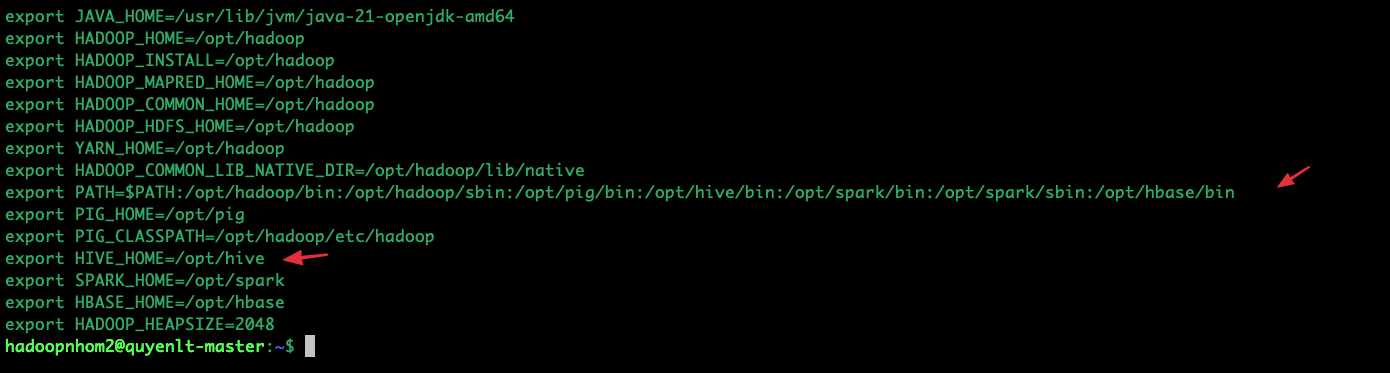
export HIVE_HOME=/opt/hive
export PATH=$PATH:/opt/hive/binsource ~/.bashrc
1.2. Khắc phục xung đột thư viện (Troubleshooting)
Vấn đề 1: Xung đột thư viện Guava giữa Hadoop và Hive. Tiến hành xóa thư viện Guava cũ của Hive và đồng bộ bằng phiên bản của Hadoop:
rm -f /opt/hive/lib/guava-*.jar
cp /opt/hadoop/share/hadoop/hdfs/lib/guava-*.jar /opt/hive/lib/
Vấn đề 2: Lỗi bảo mật "Sealing Violation" trên Java 21 do trùng lặp thư viện Derby. Để Hive có thể khởi tạo Metastore cục bộ mà không bị Java 21 đánh sập tiến trình, cần dọn sạch các phiên bản Derby có sẵn và tải chính xác 1 phiên bản duy nhất:
rm -f /opt/hive/lib/derby*.jar
wget https://repo1.maven.org/maven2/org/apache/derby/derby/10.14.2.0/derby-10.14.2.0.jar -O /opt/hive/lib/derby-10.14.2.0.jar
1.3. Cấu hình hệ thống (hive-site.xml & hive-env.sh)
Tạo tệp cấu hình hive-site.xml để khai báo cơ sở dữ liệu siêu dữ liệu (Metastore) sử dụng Derby:
nano /opt/hive/conf/hive-site.xml
Nội dung file:
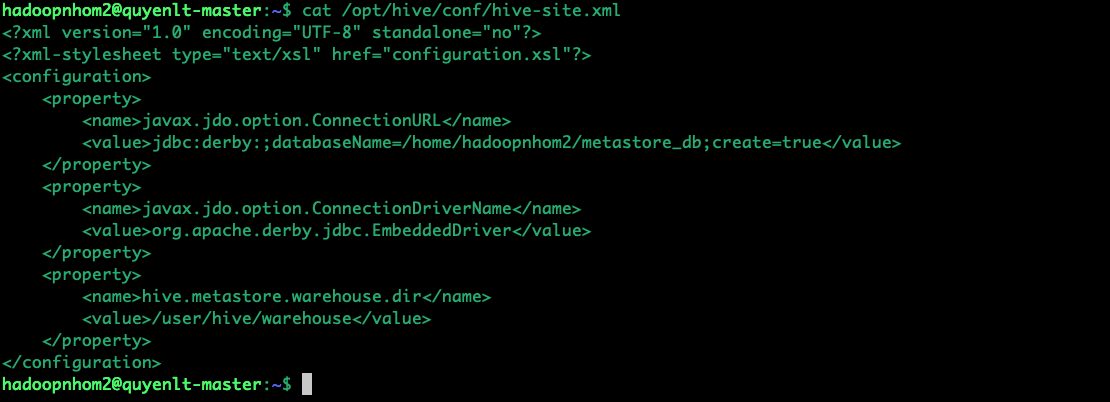
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=/home/hadoopnhom2/metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
Khắc phục lỗi OutOfMemory (OOM): Mặc định HiveServer2 chạy với lượng RAM thấp. Khi truy vấn lượng dữ liệu lớn sẽ bị treo. Tiến hành cấp phát cứng 2GB RAM cho tiến trình:
echo "export HADOOP_HEAPSIZE=2048" >> /opt/hive/conf/hive-env.sh

1.4. Khởi tạo Metastore và chạy Server
Định dạng siêu dữ liệu ban đầu cho Hive:
cd /home/hadoopnhom2
schematool -dbType derby -initSchema
schematool -dbType derby -info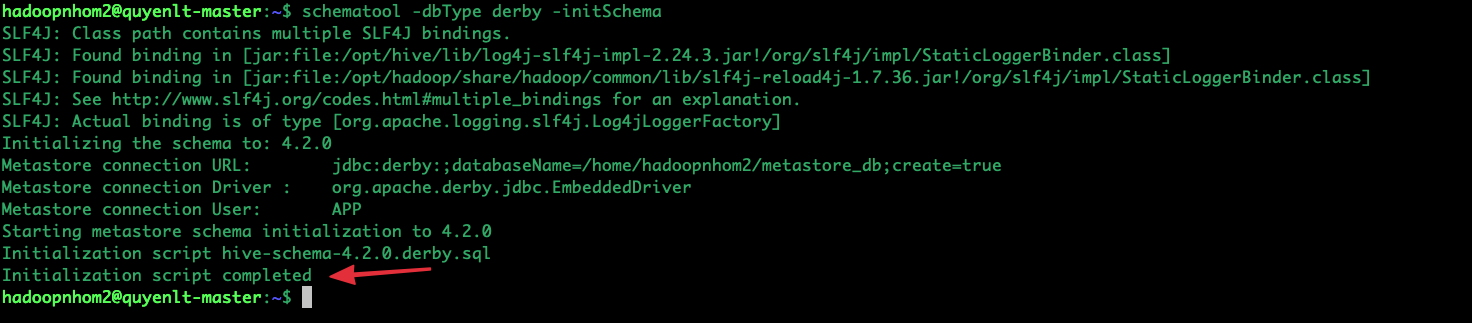
#Cách khắc phục nếu muốn start lại :hadoopnhom2@quyenlt-master:~$ pkill -f hiveserver2hadoopnhom2@quyenlt-master:~$ rm -rf /home/hadoopnhom2/metastore_dbhadoopnhom2@quyenlt-master:~$ schematool -dbType derby -initSchema
Khởi động máy chủ HiveServer2 chạy ngầm:
nohup hiveserver2 > /home/hadoopnhom2/hiveserver2.log 2>&1 &
Đợi khoảng 1-2 phút, kiểm tra cổng 10000 đã mở hay chưa: ss -tln | grep 10000

2. DEMO VẬN HÀNH APACHE HIVE (TRUY VẤN DATA WAREHOUSE)
Sau khi Server đã mở, kết nối vào Hive thông qua Beeline:
beeline -u jdbc:hive2://localhost:10000 -n hadoopnhom2
Tạo bảng External trỏ vào dữ liệu HDFS:
CREATE EXTERNAL TABLE IF NOT EXISTS airlines (
iata_code STRING,
airline STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/data/flight_project/airlines'
TBLPROPERTIES ("skip.header.line.count"="1");
CREATE EXTERNAL TABLE IF NOT EXISTS clean_flights (
year INT, month INT, day INT,
airline STRING, flight_number INT,
origin_airport STRING, destination_airport STRING,
departure_delay INT, arrival_delay INT
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/data/flight_project/clean_flights';
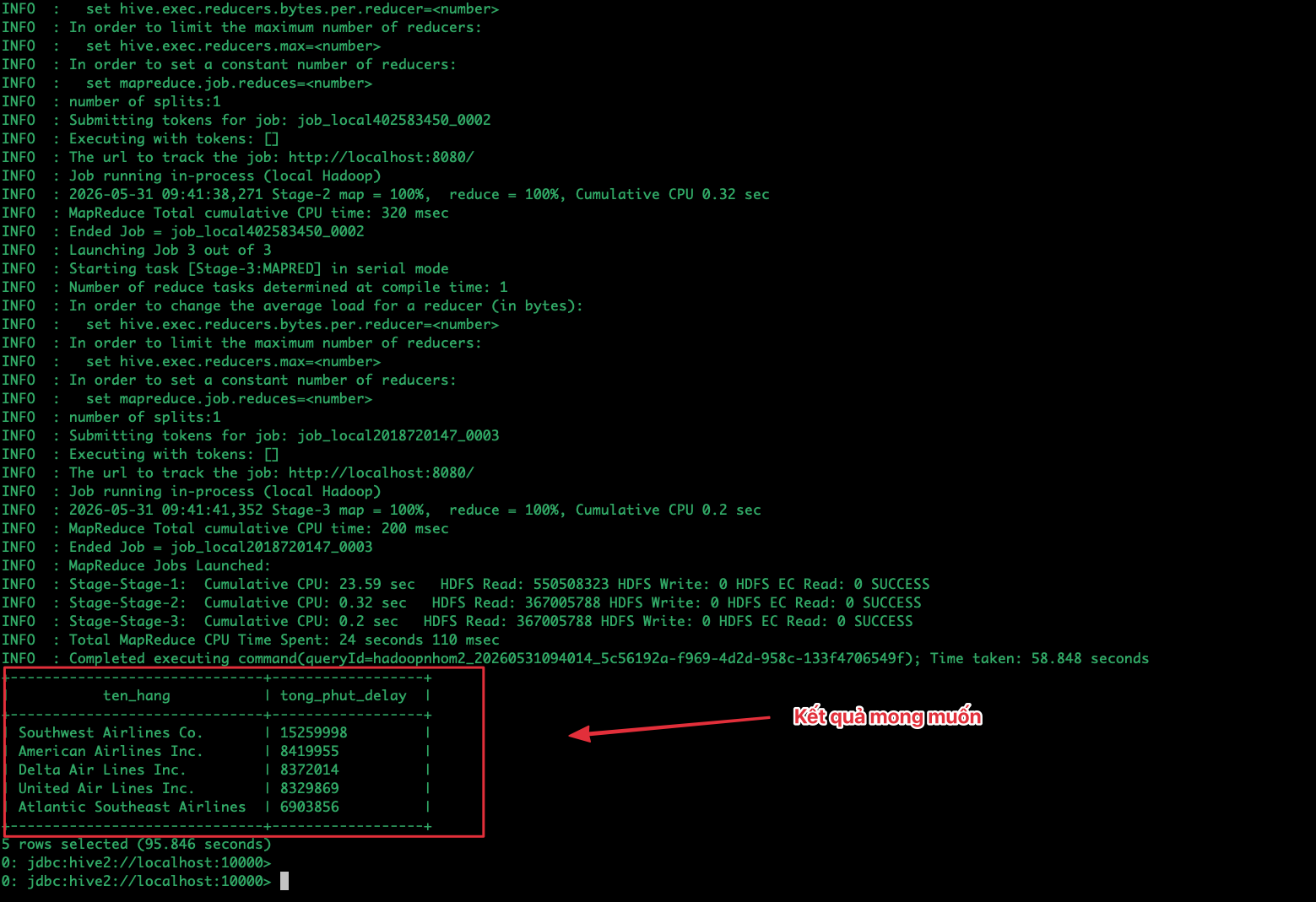
Thực thi truy vấn tìm Top 5 hãng hàng không trễ chuyến nhiều nhất: Cấu hình ép chạy chế độ Local MapReduce để tối ưu tốc độ, sau đó chạy truy vấn:
set hive.execution.engine=mr;
set mapreduce.framework.name=local;
set hive.auto.convert.join=false;

SELECT
a.airline AS ten_hang,
SUM(f.departure_delay) AS tong_phut_delay
FROM clean_flights f
JOIN airlines a ON f.airline = a.iata_code
WHERE f.departure_delay > 0
GROUP BY a.airline
ORDER BY tong_phut_delay DESC
LIMIT 5;
Ý nghĩa Demo Apache Hive: Phân tích lô (Batch Processing) & Data Warehouse
Chúng ta đang làm gì? Trong demo này, chúng ta đang đóng vai trò là những Kỹ sư Dữ liệu (Data Engineers) và Chuyên viên Phân tích (Data Analysts).
Ánh xạ dữ liệu (Schema-on-Read): Dữ liệu thô (CSV) đang nằm rải rác trên hệ thống tệp HDFS. Bằng cách tạo
EXTERNAL TABLE, chúng ta không copy dữ liệu đi đâu cả, mà chỉ "đeo một cái kính" có cấu trúc hàng/cột (SQL) lên trên đống file CSV đó.Truy vấn phân tích (OLAP): Câu lệnh
SELECT ... JOIN ... GROUP BY ... SUMyêu cầu hệ thống phải quét qua toàn bộ hàng triệu dòng dữ liệu của bảngclean_flightsvàairlines. Hive sẽ biên dịch câu SQL này thành các tác vụ MapReduce (hoặc Tez/Spark) chạy song song trên cụm phân tán để tính toán tổng số phút trễ của từng hãng.Kết quả mong đợi & Ứng dụng thực tế:
Kết quả: Một bảng báo cáo tổng hợp (Top 5 hãng hàng không có tổng thời gian delay cao nhất, ví dụ: Southwest Airlines với hơn 15.2 triệu phút). Thời gian trả kết quả thường tính bằng phút hoặc chục giây (phân tích lô - Batch).
Ứng dụng: Kết quả này không dành cho người dùng cuối (hành khách) xem trực tiếp. Nó được dùng để xuất ra các biểu đồ Dashboard (như Tableau, PowerBI) cho Ban Giám Đốc xem xét hiệu suất hoạt động của các hãng hàng không, từ đó đưa ra quyết định kinh doanh hoặc quy hoạch sân bay.
3. CÀI ĐẶT VÀ CẤU HÌNH APACHE HBASE (NOSQL)
3.1. Tải và thiết lập thư mục
Tương tự Hive, tải và giải nén HBase 2.5.14:
cd /opt
sudo wget https://dlcdn.apache.org/hbase/2.5.14/hbase-2.5.14-bin.tar.gz
sudo tar -xzf hbase-2.5.14-bin.tar.gz
sudo mv hbase-2.5.14 hbase
sudo chown -R hadoopnhom2:hadoopnhom2 /opt/hbase
hbase version

Thêm biến môi trường vào ~/.bashrc và chạy source ~/.bashrc:
export HBASE_HOME=/opt/hbase
export PATH=$PATH:/opt/hbase/bin
3.2. Cấu hình hệ thống (hbase-site.xml & hbase-env.sh)
Mở tệp hbase-env.sh và thiết lập đường dẫn Java:
echo "export JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64" >> /opt/hbase/conf/hbase-env.sh

Tiến hành cấu hình kết nối HDFS và Zookeeper trong hbase-site.xml:
nano /opt/hbase/conf/hbase-site.xml
Khắc phục sự cố (Troubleshooting): Trên nền tảng Java 21, cơ chế ghi log mặc định của HBase (AsyncFSWAL) bị chính sách bảo mật của JDK chặn lại (Lỗi ServerNotRunningYetException hoặc treo HMaster). Giải pháp là bắt buộc chuyển thuộc tính hbase.wal.provider sang dạng filesystem. Nội dung file:
<configuration>
<property><name>hbase.rootdir</name><value>hdfs://quyenlt-master:9000/hbase</value></property>
<property><name>hbase.cluster.distributed</name><value>true</value></property>
<property><name>hbase.zookeeper.quorum</name><value>quyenlt-master</value></property>
<property><name>hbase.wal.provider</name><value>filesystem</value></property>
</configuration>

3.3. Khởi động HBase
Khởi động hệ thống cơ sở dữ liệu:
start-hbase.sh
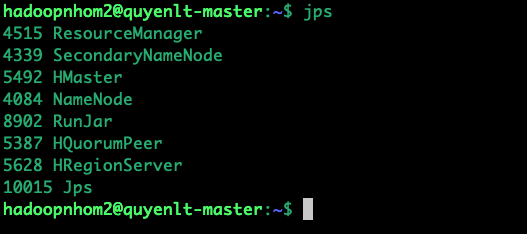
Kiểm tra tiến trình bằng lệnh jps. Các tiến trình bắt buộc phải có mặt: HMaster, HRegionServer, HQuorumPeer.
4. DEMO VẬN HÀNH APACHE HBASE (THAO TÁC NOSQL REAL-TIME)
Vào giao diện Shell của HBase:
hbase shell

Tạo bảng lưu trữ thông tin trễ chuyến (Column Family: delay_info):
create 'flight_delays', 'delay_info'

Thêm dữ liệu (Put): Mô phỏng chèn thông tin chuyến bay theo thời gian thực (Sử dụng mã chuyến bay làm RowKey).
put 'flight_delays', 'WN_123', 'delay_info:airline', 'Southwest Airlines Co.'
put 'flight_delays', 'WN_123', 'delay_info:departure_delay', '45'
put 'flight_delays', 'AA_456', 'delay_info:airline', 'American Airlines Inc.'
put 'flight_delays', 'AA_456', 'delay_info:departure_delay', '12'

Truy xuất và quét dữ liệu: Truy xuất nhanh một dòng dữ liệu theo RowKey:
get 'flight_delays', 'WN_123'

Quét toàn bộ cấu trúc bảng để thấy rõ đặc thù lưu trữ NoSQL (Tổ hợp RowKey + Column + Timestamp):
scan 'flight_delays'

Ý nghĩa Demo Apache HBase: Truy xuất thời gian thực (Real-time NoSQL)
Chúng ta đang làm gì? Lúc này, chúng ta chuyển sang góc nhìn của một Kỹ sư Hệ thống / Backend Developer (Backend Engineer).
Chuyển đổi mô hình lưu trữ: HBase không dùng SQL và cũng không dùng bảng quan hệ. Dữ liệu được lưu dưới dạng tổ hợp Key-Value vô cùng linh hoạt. Chúng ta tạo bảng
flight_delaysvới một Column Family làdelay_info.Thiết kế RowKey sinh tử: Chìa khóa của HBase nằm ở
RowKey. Trong demo, chúng ta dùng mã chuyến bay (ví dụ:WN_123) làm RowKey. Khi thực hiện lệnhput, chúng ta đang ghi trực tiếp trạng thái trễ chuyến của chuyến bayWN_123vào RAM (MemStore) và đĩa cứng (HFile) một cách tức thời.Truy xuất ngẫu nhiên (Random Read): Lệnh
get 'flight_delays', 'WN_123'không yêu cầu hệ thống quét hàng triệu chuyến bay khác. Dựa vào RowKey và cơ chế chỉ mục (B-Tree/LSM Tree) của HBase, nó "nhảy" thẳng đến đúng vị trí vật lý trên ổ cứng của máy chủ Slave đang giữ chuyến bay đó để lấy dữ liệu.Kết quả mong đợi & Ứng dụng thực tế:
Kết quả: Trả về thông tin chính xác của đúng một chuyến bay cụ thể với độ trễ cực thấp (chỉ 0.01 giây - mili-giây).
Ứng dụng: Dữ liệu này phục vụ trực tiếp cho Hành khách (End-user). Tưởng tượng một ứng dụng mobile như Flightradar24 hoặc màn hình hiển thị tại sân bay. Khi hành khách nhập mã chuyến bay
WN_123vào app, app sẽ chọc thẳng vào HBase để lấy thông tin delay và hiện lên màn hình ngay lập tức mà không có độ trễ.
Kết luận
Thông qua việc triển khai thành công 2 mô hình trên cùng một hạ tầng Hadoop, hệ thống đã chứng minh được khả năng đáp ứng toàn diện vòng đời dữ liệu. Apache Hive giải quyết bài toán vĩ mô (OLAP): Quét toàn bộ khối lượng dữ liệu khổng lồ (~600MB, hàng triệu dòng) để tìm ra các xu hướng ẩn sâu (Top 5 delay) phục vụ cho Ban quản trị, dù phải đánh đổi bằng thời gian xử lý lô. Ngược lại, Apache HBase giải quyết bài toán vi mô (OLTP): Cung cấp khả năng ghi/đọc ngẫu nhiên cực nhanh (dưới 10 mili-giây) dựa trên RowKey, phục vụ cho các ứng dụng tra cứu thời gian thực của hàng triệu người dùng cuối."