
Apache Pig: Dọn dẹp dữ liệu khổng lồ trên Hadoop Cluster (ETL)

Giả sử bạn có một cụm Hadoop phân tán đang chạy mượt mà trên AWS và một file dữ liệu thô nặng hàng GB. Bạn không thể cứ thế đẩy thẳng nó vào SQL hay Machine Learning được, vì dữ liệu thô chứa rất nhiều "rác" (dòng trống, lỗi format, dữ liệu thừa). Hôm nay, chúng ta sẽ dùng Apache Pig – một công cụ ETL (Extract, Transform, Load) cực kỳ mạnh mẽ của hệ sinh thái Hadoop – để dọn dẹp bộ dataset gần 6 triệu chuyến bay của Bộ Giao thông Vận tải Mỹ.
Điểm hay nhất? Chúng ta sẽ chạy tiến trình này từ một máy con (Slave Node) để thấy rõ sức mạnh tính toán phân tán, thay vì dồn hết tải lên máy Master!
Ở bài trước chúng ta có triển khai cụm Hadoop Cluster rồi, tiếp nối chúng ta sẽ cài thêm Apache Pig lên nó luôn nhé. Cơ sở lý thuyết của hệ sinh thái Hadoop các bạn có thể đọc ở đây.
Bước 1: Cài đặt Apache Pig trên Master
Pig không cần cài đặt phức tạp hay cấu hình file XML lằng nhằng như Hadoop. Nó thực chất là một trình biên dịch (Compiler) giúp dịch các câu lệnh Pig Latin của bạn thành các tác vụ MapReduce.
Trên máy tính (ở đây mình dùng máy master-slave), anh em tải bản Pig mới nhất về và cấu hình biến môi trường:
# Tải và giải nén (ví dụ với bản 0.17.0)
cd /opt
sudo wget https://downloads.apache.org/pig/pig-0.17.0/pig-0.17.0.tar.gz
sudo tar -xzvf pig-0.17.0.tar.gz
sudo mv pig-0.17.0 pig
sudo chown -R hadoopnhom2:hadoopnhom2 /opt/pig
# Cấu hình biến môi trường
nano ~/.bashrc
Thêm 3 dòng cực kỳ quan trọng này vào cuối file ~/.bashrc:
export PIG_HOME=/opt/pig
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$PIG_HOME/bin
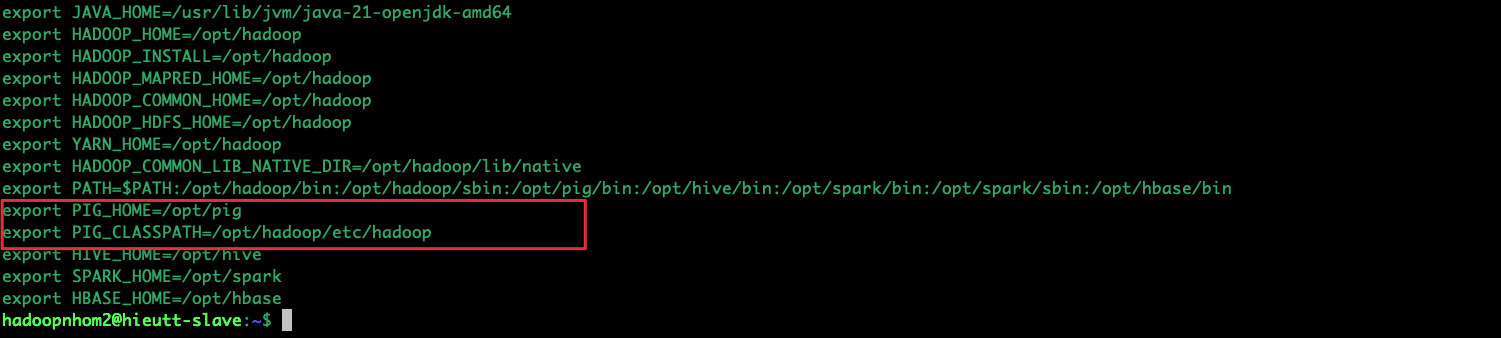
Lưu ý: Biến PIG_CLASSPATH là cốt lõi để Pig biết đường tìm đến các cấu hình HDFS của hệ thống Cluster.
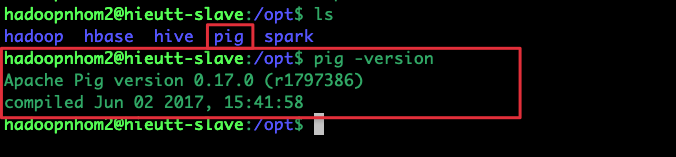
Chạy source ~/.bashrc để cập nhật. Bạn gõ thử lệnh pig -version, nếu hiện ra thông tin phiên bản là thành công.
Bước 2: Chuẩn bị Dữ Liệu (Data Ingestion)
Mình sử dụng bộ dataset 2015 Flight Delays and Cancellations (khoảng 600MB khi giải nén). Đầu tiên, mình cần tải về máy Local, sau đó bơm thẳng vào kho lưu trữ phân tán HDFS.
# Tải và giải nén dữ liệucd /tmpwget -q --show-progress https://hoctiep.quyenlt.com/archive.zipunzip -o archive.zip -d /tmp/my_dataset/# Tạo 3 thư mục riêng biệt trên HDFShdfs dfs -mkdir -p /data/flight_project/airlineshdfs dfs -mkdir -p /data/flight_project/airportshdfs dfs -mkdir -p /data/flight_project/flights# Bơm từng file CSV vào đúng thư mục của nóhdfs dfs -put -f /tmp/my_dataset/airlines.csv /data/flight_project/airlines/hdfs dfs -put -f /tmp/my_dataset/airports.csv /data/flight_project/airports/hdfs dfs -put -f /tmp/my_dataset/flights.csv /data/flight_project/flights/
Kiểm tra lại bằng lệnh hdfs dfs -ls /data/flight_project. Nếu thấy file flights.csv nằm gọn gàng trên đó thì chúng ta bắt đầu viết kịch bản dọn rác.

Bước 3: Xâm nhập vào Máy Trạm (Slave Node)
Từ màn hình Terminal của máy Master (MacTobi của bạn), Hiếu cần nhảy sang máy Slave của mình thông qua đường hầm SSH nội bộ.
# Đăng nhập sang máy hieutt-slave bằng tài khoản quản trị chung
ssh hadoopnhom2@hieutt-slave
(Nếu thành công, dấu nhắc lệnh sẽ đổi thành hadoopnhom2@hieutt-slave:~$)
Bước 4: Soạn thảo kịch bản Pig Latin (ETL Script)
Pig sử dụng ngôn ngữ Pig Latin - một dạng ngôn ngữ kịch bản cực kỳ dễ hiểu. Hiếu tạo một file kịch bản mới:
nano ~/clean_flights.pig
Copy toàn bộ đoạn code dưới đây dán vào (Ấn Ctrl + O -> Enter -> Ctrl + X để lưu):
/* 1. TẢI DỮ LIỆU TỪ HDFS */
-- Đọc file flights.csv thô và định nghĩa kiểu dữ liệu cơ bản (chararray là chuỗi)
raw_flights = LOAD '/data/flight_project/flights/flights.csv' USING PigStorage(',') AS (
year:chararray, month:chararray, day:chararray, day_of_week:chararray,
airline:chararray, flight_number:chararray, tail_number:chararray,
origin_airport:chararray, destination_airport:chararray,
scheduled_departure:chararray, departure_time:chararray, departure_delay:chararray,
taxi_out:chararray, wheels_off:chararray, scheduled_time:chararray, elapsed_time:chararray,
air_time:chararray, distance:chararray, wheels_on:chararray, taxi_in:chararray,
scheduled_arrival:chararray, arrival_time:chararray, arrival_delay:chararray,
diverted:chararray, cancelled:chararray, cancellation_reason:chararray,
air_system_delay:chararray, security_delay:chararray, airline_delay:chararray,
late_aircraft_delay:chararray, weather_delay:chararray
);
/* 2. LỌC DỮ LIỆU (DATA CLEANSING) */
-- Loại bỏ dòng Tiêu đề (Header) có chữ 'YEAR'
-- Loại bỏ các chuyến bay bị HỦY (cancelled == '1')
-- Bỏ luôn các dòng bị rỗng sân bay đi/đến
cleaned_flights = FILTER raw_flights BY
(year != 'YEAR') AND
(cancelled != '1') AND
(origin_airport != '') AND
(destination_airport != '');
/* 3. TỐI ƯU HÓA (PROJECTION) */
-- Dữ liệu gốc có 31 cột quá nặng. Chúng ta chỉ bốc ra 9 cột quan trọng nhất để làm báo cáo
final_data = FOREACH cleaned_flights GENERATE
year, month, day, airline, flight_number, origin_airport, destination_airport, departure_delay, arrival_delay;
/* 4. XUẤT XƯỞNG (STORE) */
-- Lưu kết quả đã làm sạch thành một thư mục mới trên HDFS
STORE final_data INTO '/data/flight_project/clean_flights' USING PigStorage(',');
Bước 5: Kích hoạt Lò phản ứng MapReduce
Bây giờ, Hiếu ra lệnh cho Pig dịch đoạn code trên thành các tác vụ (jobs) và gửi lên YARN để chia đều cho các máy cùng chạy:
pig -x mapreduce ~/clean_flights.pig
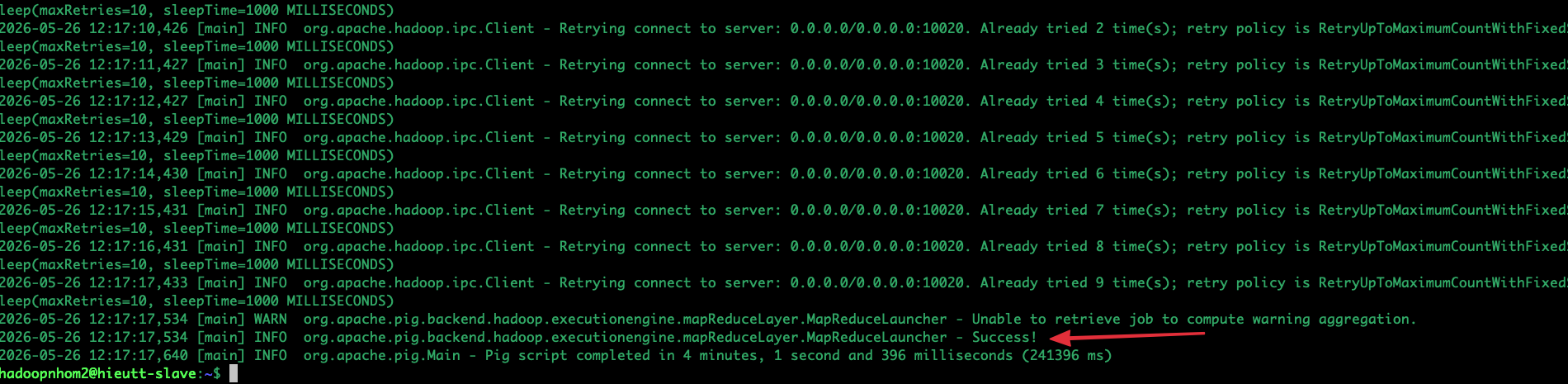
Ghi chú Demo: Khi lệnh này chạy, màn hình sẽ cuộn hàng loạt log liên quan đến MapReduce. Đây là lúc các thầy cô sẽ thấy hệ thống đang thực sự "vắt sức" xử lý dữ liệu lớn. Quá trình này sẽ mất khoảng 1 đến 5 phút để cày nát 600MB dữ liệu.
Bước 6: Nghiệm thu thành quả
Sau khi Pig báo Success!, Hiếu gõ lệnh sau để chứng minh kết quả với hội đồng:
# Xem thư mục chứa dữ liệu sạch vừa được tạo ra hdfs dfs -ls /data/flight_project/clean_flights/ # Xem thử 10 dòng đầu tiên của dữ liệu đã được dọn rác (Chỉ còn 9 cột gọn gàng) hdfs dfs -cat /data/flight_project/clean_flights/part-m-00000 | head -n 10
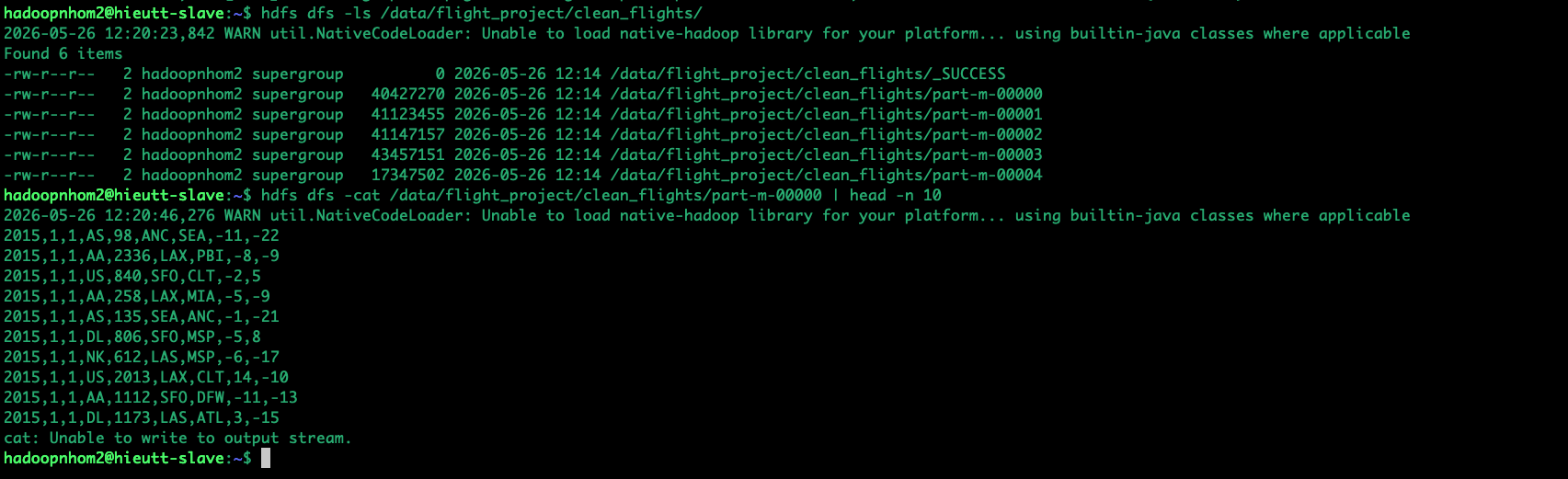
Nhìn vào log hình ảnh, mình phân tích qua :
-
Tại sao lại có tới 5 file
part-m-0000x? Đây chính là sức mạnh của MapReduce! Hệ thống đã tự động chia nhỏ file CSV 600MB ban đầu ra thành 5 phần (blocks) để các máy Slave xử lý song song cùng lúc, sau đó xuất ra 5 file kết quả tương ứng.
Chúng ta sẽ cùng "mổ xẻ" cái màn hình Terminal của Hiếu thành 3 phần rõ ràng để bạn đưa luôn vào báo cáo giải trình nhé:
2. Dòng cảnh báo màu vàng (NativeCodeLoader)
WARN util.NativeCodeLoader: Unable to load native-hadoop library...
-
Bản chất: Đây là "đặc sản" của Hadoop, gần như ai cài xong cũng gặp dòng này. Hadoop được viết bằng Java, nhưng để xử lý file tốc độ cao, nó có dùng thêm một số thư viện lõi viết bằng ngôn ngữ C/C++ (gọi là Native Library).
-
Ý nghĩa: Cảnh báo này chỉ báo rằng máy Ubuntu của Hiếu không tìm thấy thư viện C++ được biên dịch sẵn khớp 100% với hệ điều hành, nên Hadoop đã tự động chuyển sang dùng thư viện chuẩn của Java (
using builtin-java classes). -
Kết luận: Nó hoàn toàn vô hại. Dữ liệu vẫn được xử lý chuẩn xác, chỉ là tốc độ đọc ghi đĩa giảm đi khoảng 1-2% so với mức tối đa. Với đồ án này, bạn cứ tự tin lờ nó đi.
3. Mười dòng dữ liệu "Vàng" (Thành quả của Pig)
2015,1,1,AS,98,ANC,SEA,-11,-22
Nếu bạn nhớ lại kịch bản Pig Latin ở bước trước, chúng ta đã ra lệnh cắt bỏ 31 cột lộn xộn, chỉ giữ lại đúng 9 cột thiết yếu. Hãy nhìn vào dòng đầu tiên để thấy Pig đã làm việc chính xác đến mức nào:
-
2015, 1, 1: Ngày cất cánh (Năm 2015, Tháng 1, Ngày 1).
-
AS: Mã Hãng hàng không (Alaska Airlines).
-
98: Số hiệu chuyến bay (Flight Number 98).
-
ANC: Sân bay đi (Anchorage).
-
SEA: Sân bay đến (Seattle).
-
-11: Thời gian Delay lúc cất cánh (Departure Delay). Số âm (-11) nghĩa là chuyến bay này cất cánh sớm 11 phút so với lịch trình.
-
-22: Thời gian Delay lúc hạ cánh (Arrival Delay). Đến sớm 22 phút.
Nhìn vào đây, bạn thấy dữ liệu cực kỳ sạch sẽ, không có tiêu đề, không có ô trống, không có chữ thừa. Sẵn sàng 100% để bơm vào SQL.
4. Dòng lỗi màu đỏ ở cuối (Unable to write to output stream)
cat: Unable to write to output stream.
Lỗi này thực chất lại là một minh chứng cho thấy hệ thống đang hoạt động quá hoàn hảo! Lỗi này sinh ra từ cơ chế đường ống (Pipe |) của Linux:
-
Lệnh
hdfs dfs -catbên trái có nhiệm vụ: "Mở mồm" ra và đọc tuôn trào toàn bộ mấy chục triệu dòng của file 600MB. -
Lệnh
head -n 10bên phải có nhiệm vụ: Hứng đúng 10 dòng đầu tiên, in ra màn hình, rồi đóng sập cửa lại (kết thúc tiến trình). -
Lúc này, anh chàng
catbên trái vẫn đang hì hục bốc dỡ dòng thứ 11, thứ 12 để ném qua, nhưng thấy cửa đã đóng, không có nơi để xả dữ liệu ra (output stream bị ngắt), nên nó mới la lên một tiếng: "Tôi không ghi tiếp được nữa đâu nhé!".
Đây là tín hiệu ngắt (SIGPIPE) cực kỳ chuẩn mực trong Linux. Mọi thứ trong file part-m-00000 đều nguyên vẹn.
"Thay vì bắt máy Master phải cõng việc dọn dẹp dữ liệu, Slave số 1 để chạy kịch bản Apache Pig. Pig đã tự động biên dịch kịch bản thành các tác vụ MapReduce phân tán. Máy Slave số 1 vừa loại bỏ thành công hàng chục nghìn chuyến bay bị hủy trong năm 2015 và cắt giảm số cột từ 31 xuống còn 9 cột thiết yếu. Dữ liệu sạch (Clean Data) này đã được đẩy ngược lại HDFS, sẵn sàng cho Master đẩy vào Kho dữ liệu (Data Warehouse) để lập báo cáo tổng hợp."
Kết luận
Chỉ với vài chục dòng code đơn giản, Apache Pig đã giúp chúng ta giải quyết bài toán tiền xử lý mà không cần phải viết những đoạn code Java MapReduce dài dòng và phức tạp.
Ở bài viết tiếp theo, mình sẽ hướng dẫn cách dùng Apache Hive để trích xuất báo cáo từ đống dữ liệu sạch này bằng SQL. Hẹn gặp lại anh em!