
Hadoop Ecosystem: Cài đặt, Cấu hình và vận hành Apache Spark

Ở bài trước chúng ta đã sử dụng Hive và Hbase để truy vấn Database, tiếp tới trong các framework áp dụng cho Hadoop Ecosystem sẽ là Apache Spark, cơ sở lý thuyết mọi người có thể tham khảo ở đây.
Mục tiêu của phần này: Tích hợp Apache Spark vào cụm Hadoop hiện có để tận dụng sức mạnh xử lý dữ liệu trên bộ nhớ (RAM). Spark sẽ được cấu hình để đọc dữ liệu thô từ HDFS và sử dụng YARN làm bộ điều phối tài nguyên (Cluster Manager).
1. CÀI ĐẶT VÀ CẤU HÌNH APACHE SPARK
1.1. Tải và thiết lập thư mục
Tải gói cài đặt Apache Spark 3.5.8 (phiên bản được biên dịch sẵn cho Hadoop 3) từ máy chủ Apache và giải nén vào thư mục /opt:
cd /opt
sudo wget https://dlcdn.apache.org/spark/spark-3.5.8/spark-3.5.8-bin-hadoop3.tgz
sudo tar -xzf spark-3.5.8-bin-hadoop3.tgz
sudo mv spark-3.5.8-bin-hadoop3 spark
sudo chown -R hadoopnhom2:hadoopnhom2 /opt/spark
spark-submit --version 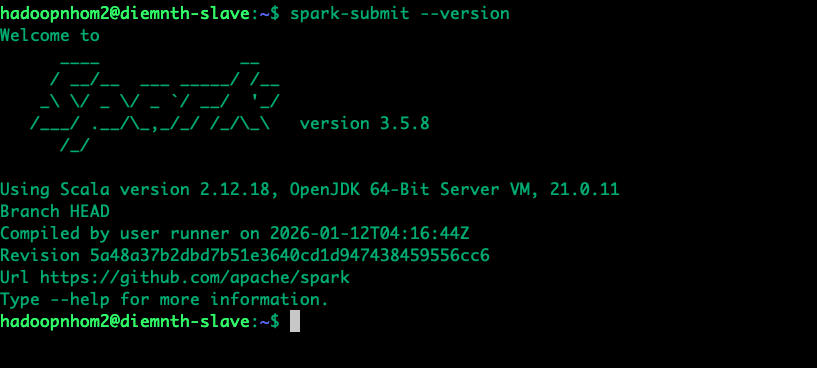
Thiết lập biến môi trường toàn cục cho Spark bằng cách mở file ~/.bashrc:
nano ~/.bashrc
Thêm các dòng sau vào cuối file để hệ thống nhận diện được các lệnh của Spark:
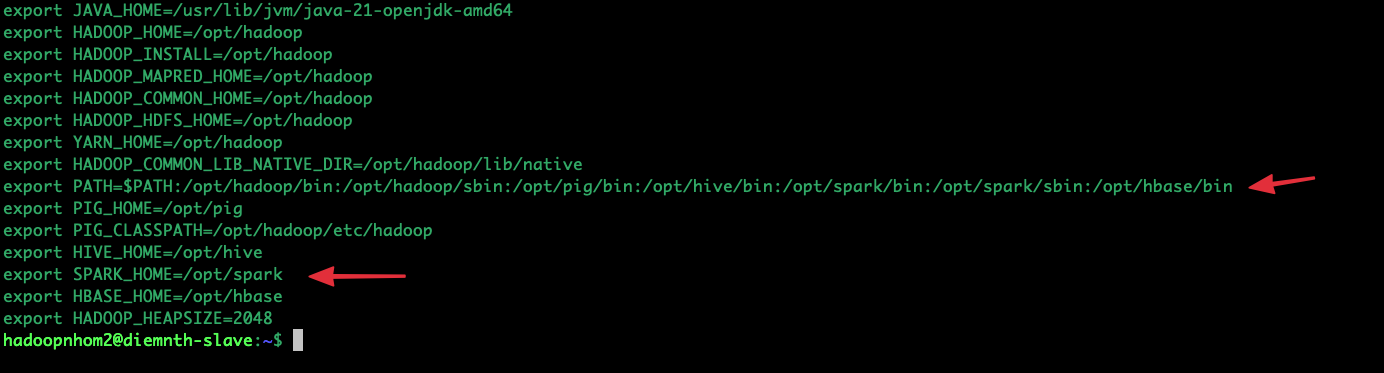
export SPARK_HOME=/opt/spark
export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin
Lưu file và nạp lại cấu hình:
source ~/.bashrc
1.2. Cấu hình tích hợp Spark với Hadoop (YARN & HDFS)
Điểm mấu chốt (Khắc phục sự cố): Mặc định, Spark không tự biết cụm Hadoop của bạn nằm ở đâu. Nếu không chỉ đường, Spark sẽ chạy ở chế độ cục bộ (Local) và không thể đọc được file trên HDFS. Bạn cần khai báo biến môi trường HADOOP_CONF_DIR để Spark đọc được các file cấu hình core-site.xml và yarn-site.xml.
Tạo file cấu hình môi trường cho Spark từ file mẫu:
cp /opt/spark/conf/spark-env.sh.template /opt/spark/conf/spark-env.sh
nano /opt/spark/conf/spark-env.sh
Thêm dòng khai báo vị trí cấu hình Hadoop vào cuối file:
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop

2. DEMO VẬN HÀNH APACHE SPARK (PYSPARK & DATAFRAME API)
Thay vì dùng SQL thuần túy như Hive, Diễm sẽ trình bày sức mạnh của Spark thông qua PySpark (Spark kết hợp với ngôn ngữ Python) – công cụ tiêu chuẩn hiện nay của các Data Scientist và Data Engineer.
Bước 1: Khởi động môi trường PySpark trên cụm YARN
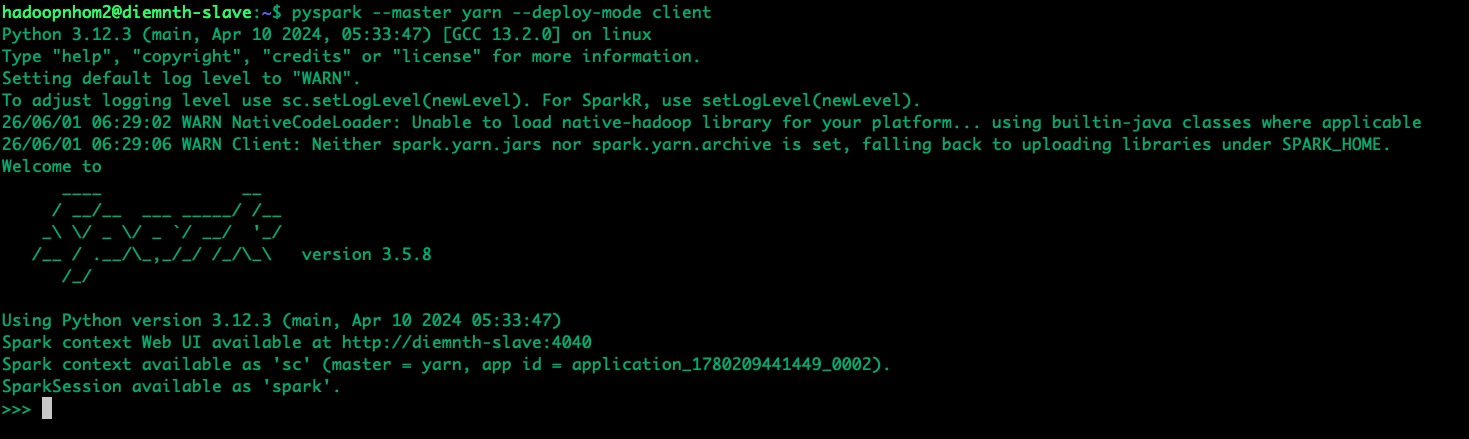
Sử dụng lệnh sau để mở giao diện tương tác PySpark, đồng thời yêu cầu YARN cấp phát tài nguyên cho tác vụ này:
pyspark --master yarn --deploy-mode client
Bước 2: Viết mã xử lý dữ liệu (Data Processing)
Tại dấu nhắc lệnh >>> của PySpark, thực thi lần lượt các khối lệnh Python sau để phân tích dữ liệu Flight Project (~600MB) đang nằm trên HDFS:
1. Đọc dữ liệu từ HDFS vào Spark DataFrame:
# Đọc file CSV từ HDFS, ép kiểu dữ liệu tự động (inferSchema)
df = spark.read.csv("hdfs://quyenlt-master:9000/data/flight_project/clean_flights", header=False, inferSchema=True)
# Gắn tên cột do file dữ liệu gốc không có Header
df_flights = df.toDF("year", "month", "day", "airline", "flight_number", "origin_airport", "destination_airport", "departure_delay", "arrival_delay")

2. Đăng ký View để kết hợp API DataFrame và SQL:
df_flights.createOrReplaceTempView("flights")
3. Bài toán phân tích phức tạp: Nhiệm vụ: Tìm Top 5 đường bay (Origin -> Destination) có tần suất hoạt động cao (trên 50 chuyến) nhưng lại có số phút trễ trung bình tồi tệ nhất.
result = spark.sql("""
SELECT origin_airport, destination_airport,
ROUND(AVG(departure_delay), 2) as avg_delay,
COUNT(*) as total_flights
FROM flights
WHERE departure_delay > 0
GROUP BY origin_airport, destination_airport
HAVING total_flights > 50
ORDER BY avg_delay DESC
LIMIT 5
""")
# Kích hoạt hành động (Action) để Spark bắt đầu tính toán và in kết quả
result.show()
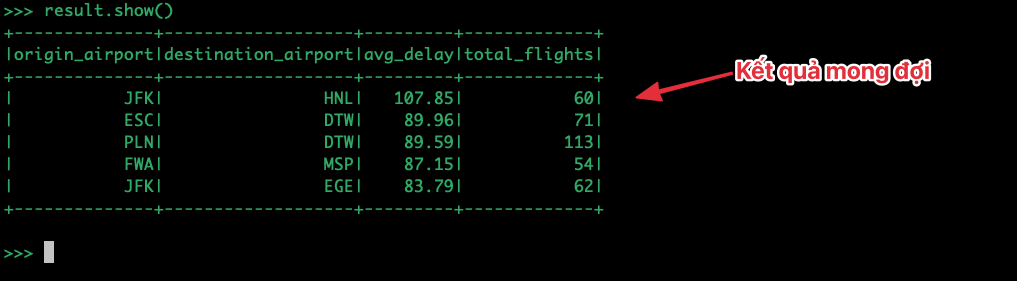
(Lúc này Spark sẽ tính toán cực nhanh, hiển thị thanh Progress Bar của các Stage, thể hiện sức mạnh vượt trội so với MapReduce).
3. Ý NGHĨA DEMO APACHE SPARK (Đưa vào báo cáo)
Để làm bật lên vai trò của spark trong phần này, cần giải thích rõ sự khác biệt của hệ thống vừa demo:
Chúng ta đang làm gì? Khác với dùng Hive (dịch SQL ra MapReduce để ghi/đọc liên tục xuống ổ cứng), Spark đang sử dụng cấu trúc dữ liệu DataFrame của Spark.
-
Khi gọi lệnh
spark.read.csv, Spark kéo dữ liệu từ ổ cứng của cụm HDFS và tải trực tiếp lên bộ nhớ RAM của các máy chủ phân tán (Worker Nodes). -
Spark áp dụng cơ chế Lazy Evaluation (Đánh giá lười biếng) – nó chỉ lập biểu đồ tính toán (DAG) chứ chưa chạy ngay. Chỉ khi gọi lệnh
result.show(), cụm mới bùng nổ sức mạnh xử lý song song.
Tại sao lại cần Spark khi đã có Hive? (Giá trị cốt lõi)
-
Tốc độ (Speed): Phép tính trung bình (
AVG) và nhóm (GROUP BY) trên tập dữ liệu lớn đòi hỏi thao tác xáo trộn dữ liệu (Shuffle) rất nặng. Nhờ thực hiện In-Memory (trên RAM), đoạn code PySpark trên trả về kết quả chỉ trong vài giây, nhanh hơn gấp 10-100 lần so với Hive MapReduce. -
Mở rộng linh hoạt: Hive chỉ mạnh về SQL. Còn Spark (thông qua PySpark) cho phép áp dụng các thư viện Python để xử lý dữ liệu phức tạp hơn, làm tiền đề để bơm luồng dữ liệu này vào các mô hình Học máy (Machine Learning) bằng thư viện
Spark MLlibtrong tương lai.
Tóm tắt sự phân công hệ thống của nhóm: > Dữ liệu thô trên HDFS -> Hive đóng vai trò kho lưu trữ tổng hợp dài hạn (Data Warehouse) -> Spark đóng vai trò động cơ xử lý phân tích nâng cao, tính toán tốc độ cao (Analytics Engine) -> HBase đóng vai trò phục vụ truy xuất tức thời cho ứng dụng người dùng (Real-time NoSQL). Cả 3 công nghệ tạo nên một kiến trúc Big Data hoàn hảo và toàn diện!